Fault tolerance patterns for microservicesloper

Dealing with failures and making distributed systems fault-tolerant is such a vast topic that we cannot discuss enough in just a blog post. Therefore, we will talk about a small subset of this topic in this blog post, dealing with failure when communicating between our services.
Failure is everywhere
According to this Fallacies of distributed systems. Your HTTP request will either fail at some point due to network error or take a very long time to respond.
It’s not just about the network but the failures. Let’s think about something else like your hard drive, what would happen if you read a file but it doesn’t exist because someone deleted it, or even worse, the hard drive failed? What if one of your servers just crashed for no particular reason? What if your Database somehow cannot be connected? Shortages? After all, failure is everywhere and cannot be prevented completely.
What is fault tolerance?
Fault tolerance in computer systems refers to the ability of a system to continue operating without interruption when one or more of its components fail.
As mentioned in the above section, failure is everywhere and inevitable, we cannot prevent it but aim to detect, isolate, and resolve problems preemptively.
That’s enough information about failure and fault-tolerant systems. Let’s dive into some patterns when making HTTP requests between services. (These examples below are written in C# and .NET Core project, the syntax may be different for other languages but the pattern should remain the same).
Timeout pattern
A slow HTTP request doesn’t degrade your system but a bunch of slow HTTP requests does. It doesn’t matter whether you are making a GET request to serve the data to the client or just simply exchanging information between services.
Let’s take a look at the example below, service A is requesting Service B, it takes roughly 30s for Service B to produce a response. That’s slow but still works.
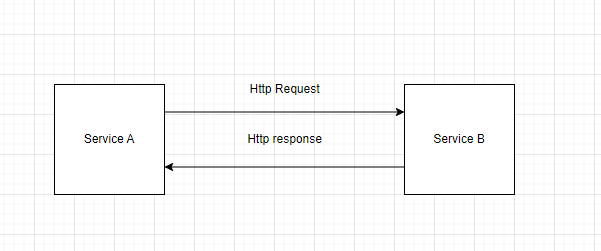
Figure 1: Communication between Service A and Service B demonstration
If we scale this scenario up to 30 users requesting service A to service B, these requests hold 30 Ephemeral sockets for 30 seconds waiting for responses from service B.
In this example, Service A has id 26900, Service B has process id 32176. Take a look at these sockets being held by process A, the resource could be exhausted if the number of requests goes up.
![]()
Figure 2: Process Id of Service A and Service B in Task Manager
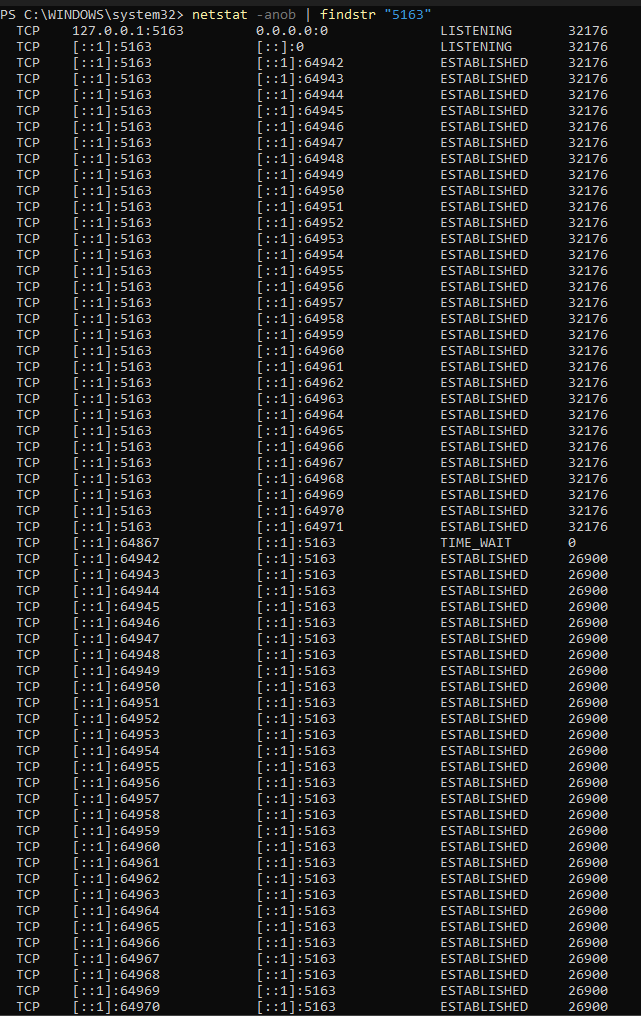
Figure 3: Ephemeral sockets hold by Service A
That’s a lot of resources, the waiting time is not even acceptable for the user. That’s why we came up with the Time Out pattern. If the request takes longer than expected, we just give up.
The good thing about the Time Out pattern is that we can detect slow-running operations and give up before it consumes all the resources. There’s a downside of this pattern, you have to configure the timeout threshold appropriately so your system remains responsive and doesn’t drop your requests if sometimes they take a bit longer than expected.
Timeout pattern implementation
For the sake of simplicity, we will use Polly.NET for all our examples in this post. It’s a library that helps us implement a resilience system so we don’t have to write all the boilerplate code.
After initiating the source, you need to add the package Microsoft.Extensions.Http.Polly to your project via Nuget Package Manager or via command dotnet add package Microsoft.Extensions.Http.Polly if you are using dotnet cli.
First, we define the timeout policy in your Program.cs file (If you are using an older version of .NET core, add them to Startup.cs ConfigureServices method instead).

Figure 4: Defining timeout policy
When you bootstrap your HttpClient via method AddHttpClient(“”), add these following lines of code.

Figure 5: Use timeout policy when configuring HttpClient
Let’s create a HttpClient from IHttpClientFactory and use it to see if our code works.
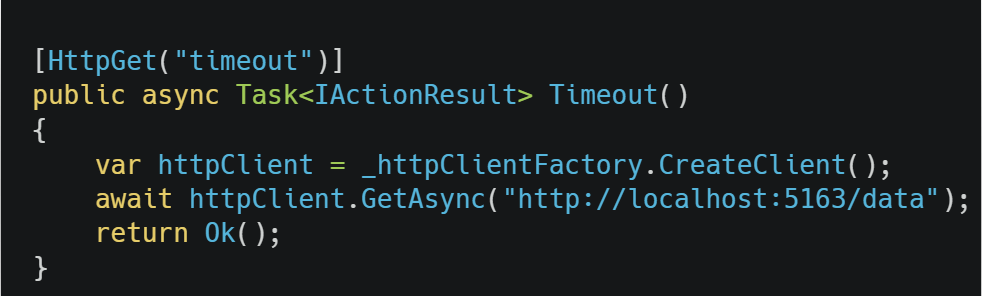 Figure 6: Create a HttpClient from IHttpClientFactory and make a request
Figure 6: Create a HttpClient from IHttpClientFactory and make a request
Our request took more than 5 seconds to respond and a TimeOutRejectedException was thrown.
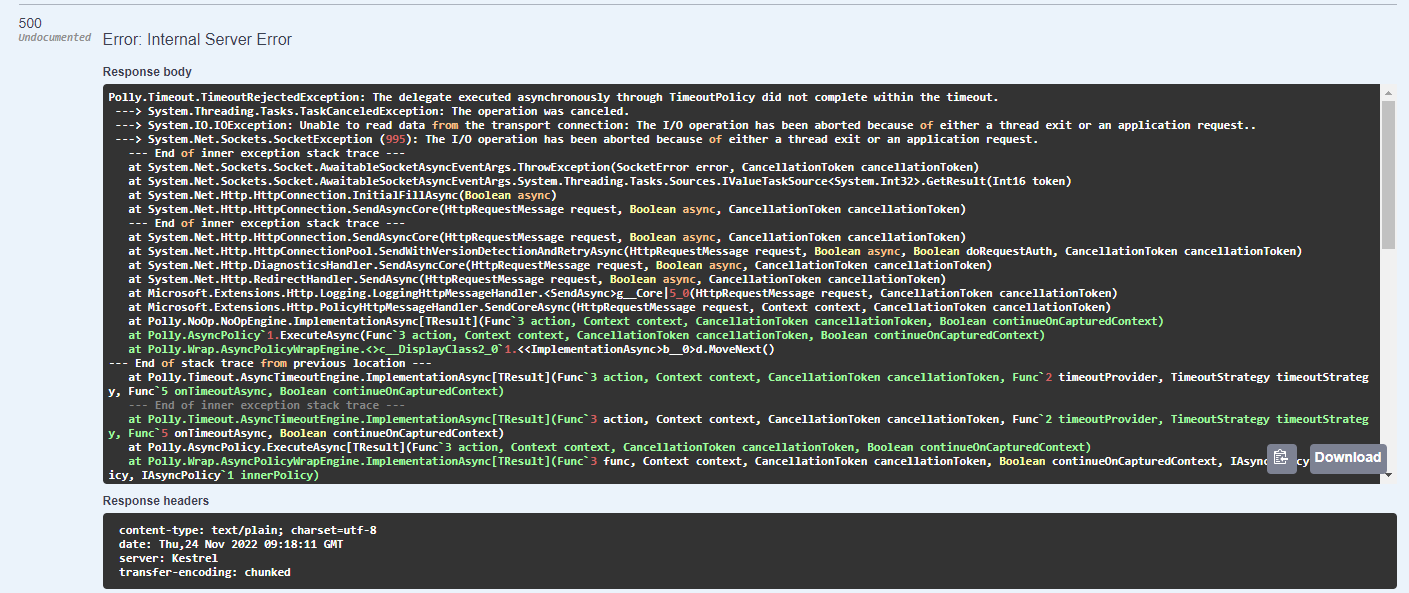
Figure 7: TimeOutRejectedException on request timeout
The good thing about Polly’s implementation is that there are a lot of overloads to suit our needs. For example, we can execute some code when the request is timed out by adding a callback like this:
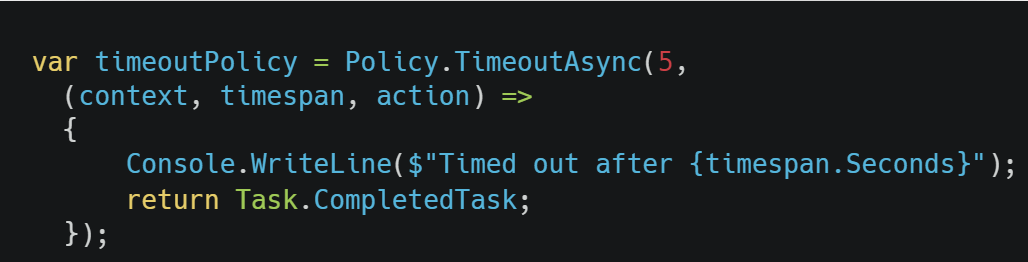
Figure 8: Add a callback when timeout happens
This code will be executed every time the request timed out.
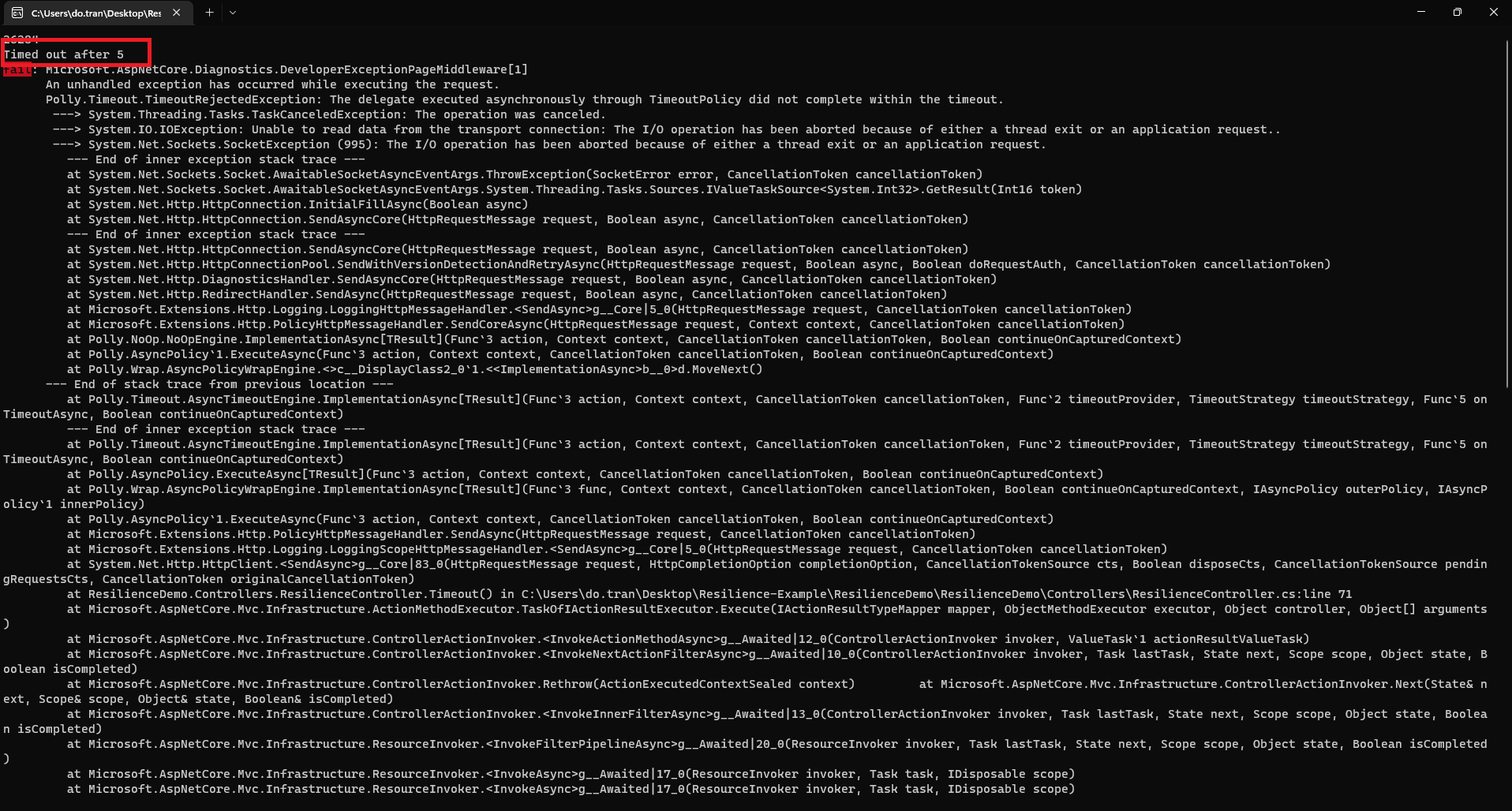 Figure 9: Callback gets executed when timeout happens
Figure 9: Callback gets executed when timeout happens
Retry Pattern
Sometimes, a component or a service is just unavailable for a short period, this kind of fault is called “transient fault” and usually takes a short time to go away. This usually happens during maintenance or recovery from a crash. In this scenario, it makes sense if we retry the request rather than log the error and abort it.
Before you implement the retry pattern, there’s a couple of points you need to consider:
– Is the failure transient? If the answer is yes, you should retry because the error seems to disappear quickly. If the answer is No (for example, you get Unauthorized error) this kind of error is not gonna disappear quickly, the pattern does nothing helpful here but add another layer of complexity and overhead.
– How long should we delay between each retry? For tasks like serving data to the client, the delay should be as short as possible. However, if you are doing some long-running or background tasks, the delay should be long enough for another service to be alive.
This pattern also has a downside, if your service is dead or having difficulties to recover. The pattern would add more pressure to the service.
Retry pattern implementation
Add these lines to your Program.cs file just like in the previous example.

Figure 10: Add retry policy when configuring HttpClient
Then inject IHttpClientFactory in your class and create HttpClient like this.
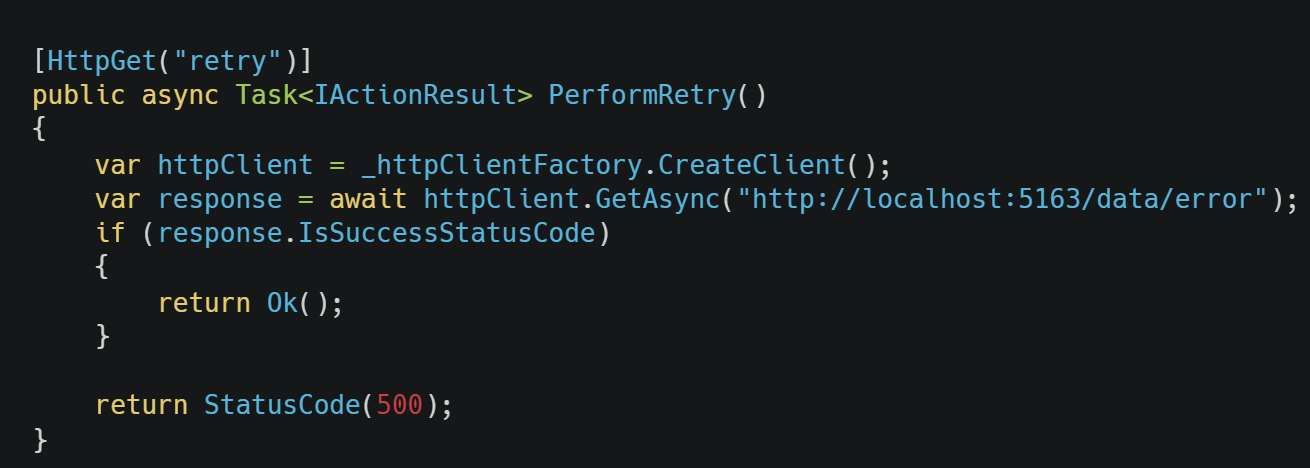 Figure 11: HttpClient usage
Figure 11: HttpClient usage
From now on, whenever you create an HttpClient using IHttpClientFactory. Retrieving 5xx status code, 408 status code or a Network failure (System.Net.Http.HttpRequestException) would result in 3 retries.
If the predefined policies of Polly don’t suit your needs, refer here for more custom configurations and policies.
Circuit breaker
Besides transient faults, there can also be situations where the retry fails so many times. In this case, we can’t just keep retrying forever, we should take a break and give the other service time to recover before we can try again.
A circuit breaker acts as a proxy for operations that may fail (in this case, it’s our HTTP request). This proxy monitors the number of recent failures, and then uses this information to decide whether to allow the operations to proceed or simply return an exception.
The proxy could be viewed as a state machine that mimics the functionality of an electrical circuit breaker:
Closed: The proxy maintains a count of recent failures, If a request fails, it increases the counter by one. If the counter exceeds the threshold, it changes to an Open state and starts a timer, when this timer expires, the proxy switches to a half-open state.
Open: In this state, any HTTP request fails immediately and an exception is returned.
Half-Open: A limited number of requests are allowed to pass through, if all those requests are successful, the state is changed back to Closed. If any of them fails, the proxy assumes that the problem is still present and hasn’t been fixed yet so it reverts back to the Open state and restarts the timer again.
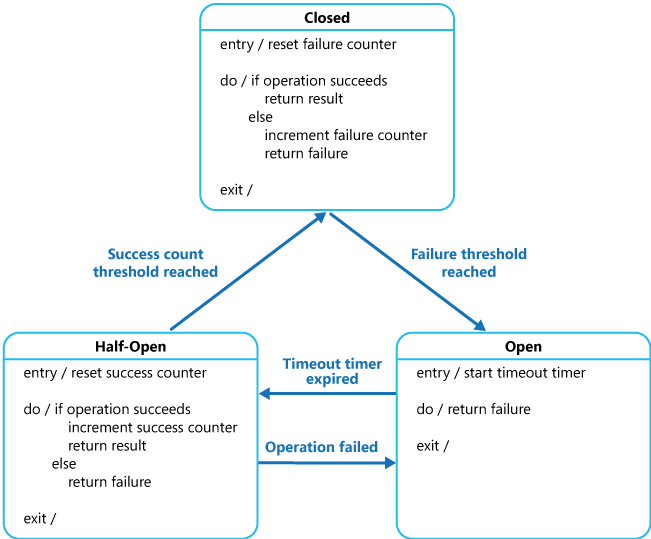
Figure 12: 3 States of circuit breaker
Circuit breaker implementation
To define this pattern. First, we create a Polly’s policy.
 Figure 13: Create the circuit breaker policy.
Figure 13: Create the circuit breaker policy.
Then, add this policy to IHttpClientBuilder using the extension method AddPolicyHandler like this.

Figure 14: Use circuit breaker policy when configuring HttpClient.
The consumer code of IHttpClientFactory should be the same as the Retry pattern.
From now on, if your requests fail 5 times in a row, it will take a break for 30 seconds, any requests made in this 30s period will be automatically returned immediately with the exception BrokenCircuitBreakerException.
After that 30s, if your first request succeeds, the state of the circuit will be changed back to Closed, otherwise it will be set back to Open and wait for another 30s.
If the default behavior doesn’t cover your need or you want to manually control the circuit, you can find out how to customize it here.
Bulkhead pattern
The Bulkhead pattern is a type of application design that is tolerant of failure. It’s all about isolation, resources consumed for communication with one service should not affect the communication with another service.
For example: Your service has 2 third-party integrations. Let’s call the first one Service A and the other is Service B.
If Service A is not available, all the failed requests your service makes to Service A will quickly stack up and cannot be released promptly. Those requests to service B soon will be affected (because we use the same resource for making requests to both services). Bulkhead pattern prevents this by isolating the resource usage of services A and B. Therefore, if Service A failures stack up, it would not affect Service B at all.
Bulkhead pattern implementation
In your Program.cs, create the bulkhead policy like the code below.

Figure 15: Create a bulkhead policy
Then, we can use the bulkheadPolicy as follow:
Figure 16: Use bulkhead policy when configuring HttpClient.
In this case, we allow only 1 concurrent request at a time, if more than 1 request is sent, your code will throw a BulkheadRejectedException.
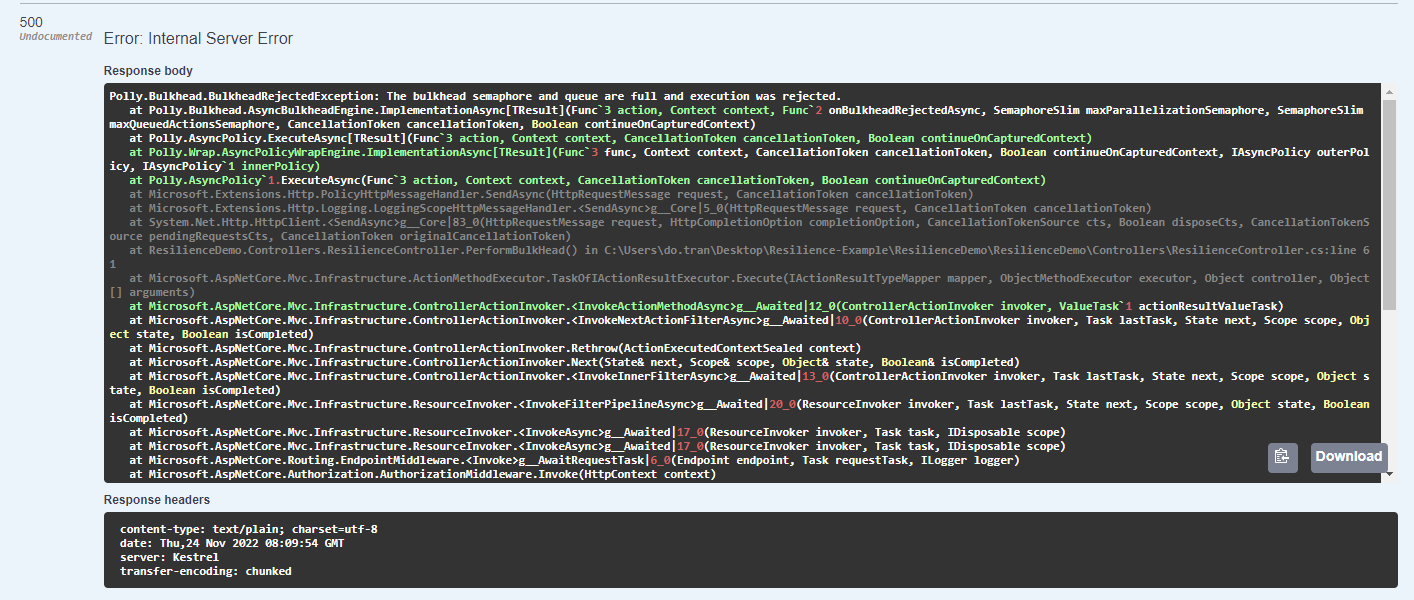 Figure 17: BulkheadRejectionException thrown if resource exceeds the limit.
Figure 17: BulkheadRejectionException thrown if resource exceeds the limit.
Polly allows us to be more flexible by adding some overload to the BulkHeadAsync method which allows us to queue the requests and handle rejection via params maxQueuingActions and onBulkheadRejectedAsync. You can read about it more here.
 Figure 18: Another overload of BulkheadAsync method with more parameters
Figure 18: Another overload of BulkheadAsync method with more parameters
I hope this brief introduction to failures, fault-tolerance system,s and fault-handling can help you to think differently about your problem.
With our series of .NET articles, we hope you can gain valuable knowledge to solve your challenges. Got questions about .NET development? Reach out to us anytime! We’ve completed hundreds of .NET projects. Let us help you overcome challenges.
Resources:
Source code: https://github.com/dotransts/resilience-dotnet
References:
https://learn.microsoft.com/en-us/azure/architecture/patterns/circuit-breaker
https://learn.microsoft.com/en-us/azure/architecture/patterns/retry
https://learn.microsoft.com/en-us/azure/architecture/patterns/bulkhead
https://github.com/App-vNext/Polly#timeout

.NET Development Services
Related articles

Java or .NET For Web Application Development

What You Need to Know about State Management: 6 Techniques for ASP.NET Core MVC

Unlocking the Potential of .NET MAUI for Frontend and Web Developers
")
Build Customer Service (.NET, Minimal API, and PostgreSQL)

Say Hello to .NET MAUI

How to build UI with .NET MAUI


