Amazon S3: First look and simple demo to upload image to S3 with Presigned url

1/ What is Amazon S3?
Amazon S3 stands for Amazon Simple Storage Services, it is one of the most fundamental services of Amazon Web Service (AWS). It’s a cloud-based storage service, designed to store and retrieve any amount of data from anywhere.
Amazon S3 supports almost all cases of store and retrieve purposes: data lakes, websites, backup and restore, archive, big data analytics.
2/ Main Concepts
Amazon S3 stored our file as an object. Like other storage services, Amazon S3 provides scalability, data availability, security and it’s suitable for users of all sizes and industries. Let’s take a look into the main concepts of Amazon S3 with the most simple way to understand it.
2.1/ How Amazon S3 works
Amazon S3 stands as a comprehensive object storage solution, housing data in the form of objects organized within containers known as buckets. An object encompasses a file along with any associated metadata that provides additional information about the file. A bucket is a container for objects. Buckets and the objects in them are private by default. In short, Amazon S3 doesn’t care about our file extension name. It serves everything as a file, so it only cares about file data and meta-data, which make up the definition of a file.
2.2/ Bucket
A bucket serves as a storage container for objects housed within the Amazon S3 service. We can store any number of objects in a bucket and we can create up to 100 buckets in one account. We can choose the region where the bucket resides, it will help us to optimize latency, minimize costs.
Bucket name is globally unique and we cannot rename it after we create it. Bucket is also the highest level of Amazon S3 namespace. It provides access control options, such as bucket policies, access control list(ACL) and S3 Access Points to help us manage our resources on S3.
2.3/ Object
Object is the fundamental entity stored in Amazon S3. An object consists of object data and metadata.
Metadata refers to a collection of name-value pairs that characterize an object. This set includes default metadata, like the date of the last modification, as well as standard HTTP metadata such as Content-Type. Additionally, users have the flexibility to define custom metadata during the object storage process.
Object is uniquely identified within a bucket by a key (name) and a version ID(in case we enable S3 Versioning, it will help us to store multiple versions of an object).
2.4/ Keys
An object key, also known as a key name, serves as the distinctive identifier for an object within a bucket. The amalgamation of a bucket, object key, and, if applicable, a version ID (when S3 Versioning is activated for the bucket) collectively ensures the unique identification of each object.
For example: https://saigon-technology-react-node-bucket.s3.ap-southeast-1.amazonaws.com/photos/aws-s3.jpg
Saigon-technology-react-node-bucket: bucket name
ap-southeast-1: bucket’s region
photos/aws-s3.jpg: object’s key
2.5/ S3 Versioning & Version ID
Amazon S3 supports us to keep multiple variants of an object in the same bucket. When we enable S3 Versioning, we can preserve, retrieve, and restore every version of every object stored in our buckets. Each version has a unique version ID, combined with object key, we can retrieve every version of each object.
For example:
https://saigon-technology-react-node-bucket.s3.ap-southeast-1.amazonaws.com/photos/aws-s3.jpg?versionId=uy3tEPM5GfiApxOwCniSVmkz9uZdG1aL
Saigon-technology-react-node-bucket: bucket name
ap-southeast-1: bucket’s region
photos/aws-s3.jpg: object’s key
uy3tEPM5GfiApxOwCniSVmkz9uZdG1aL: version ID
2.6 Bucket Policy
Bucket policy is a resource based on AWS Identity and Access.
Management policy. A bucket policy serves as a tool to bestow access permissions to both the bucket and its contents. Notably, only the owner of the bucket possesses the authority to associate a policy with it. The permissions specified within the bucket policy extend uniformly to all objects residing in the bucket that fall under the ownership of the bucket owner.
Bucket policy uses JSON standard format, making it easy to read and understand. We can use bucket policy to add or deny permissions for the object in a bucket. It allows or denies requests based on the element in policy, including the requester, the action, the resource or the addition of the request(for example, the IP address used to make the request).
For example, we can create a bucket policy that grants anonymous user permissions to upload objects to our S3 bucket while ensuring that we have full control of the uploaded objects.
2.7 Access Control List
Access Control List(ACL) is used to grant read and write permission to authorized users for individual buckets and objects. ACL will define which AWS accounts or groups are granted access and the type of access.
2.8 Region
As I mentioned above, we can choose a geographical AWS Region where Amazon S3 stores the buckets that we create. With AWS S3 Region, we can optimize latency, minimize costs, or address regulatory requirements.
2.9 Data consistency model
Amazon S3 following eventual consistency model, it means Amazon S3 will ensure that our data will be updated/created, but it will be done in some time. It will lead to mis-match in some scenario where you delete a bucket and immediately list all buckets, the deleted bucket might still appear in the list. We will get a deeper look of the eventual consistency model with 3 simple examples.
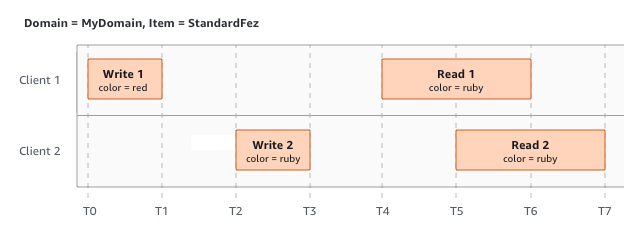
When client 1 and client 2 request to read the object after both 2 write requests complete, it will have the same consistent result with color = ruby.
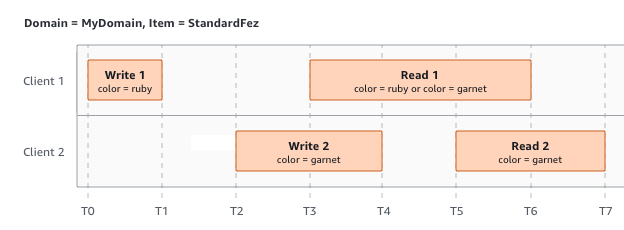
When client 1 requests to read while Amazon S3 is still processing request write 2, client will get both ruby or garnet in this case.

The last one will be complicated, write 2 begin requests before write 1 completes. Therefore, these writes are considered concurrent. However, the order in which Amazon S3 receives the requests and the order in which requests completes cannot be predicted because of various factors, such as network latency. The best way to determine the final value is to perform a read after both writes have been completed.
3/ Use cases
Amazon S3 supports almost all cases of store and retrieve purposes: analytic data, store log files, store application data, store static files such as video, picture or backup and archival purposes. For these purposes, all we need to do is create a bucket on Amazon S3 and transfer our data into it. Amazon S3 will help us to control the access to data, optimize the cost with several storage classes(of course, money is important), replicate data to any region in case we need to support people over the world, protect and secure our data with encryption…
Beside that, Amazon S3 also supports one case that is very simple and funny: help us to host the static website.
4/ Presigned-url
All objects and buckets are private by default. With bucket policy, we only can grant the permissions for other AWS accounts and the groups of users. But what if we want to give the anonymous user the permissions to upload and get a file from our bucket? That’s why I bring to you Pre-signed url, the most simple and optimized way to upload and get files.
Presigned URL is used to optionally share objects or allow users to upload objects to buckets. When we create a pre-signed URL, we associate it with a specific action. We can share the URL, and anyone with access to it can perform the action embedded in the URL as if they were the original signing user.
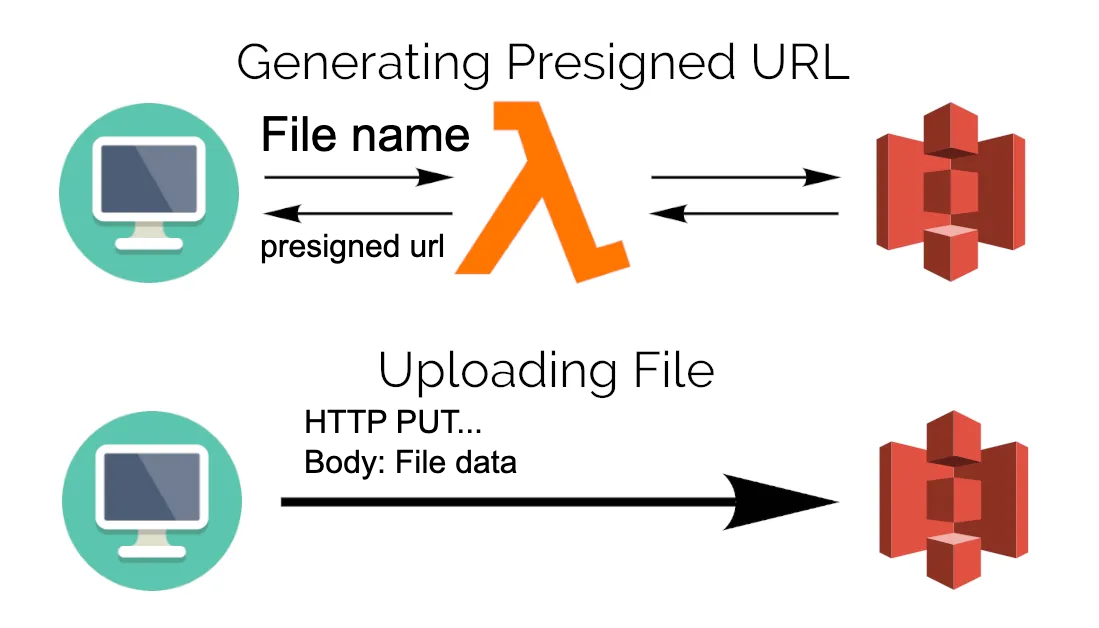
Uploading a file using a pre-signed url is simply easy. The client will request to the server, after that server will request to Amazon S3 to generate a pre-signed url. It means our server told Amazon S3 that the client will upload a file into S3 with this link. Of course we can check which type of file, which limited size of file, which domain is accepted to upload.

But why do we need to use a pre-signed url while it takes 2 steps to upload a file, while uploading directly from client to server requires only 1 step?
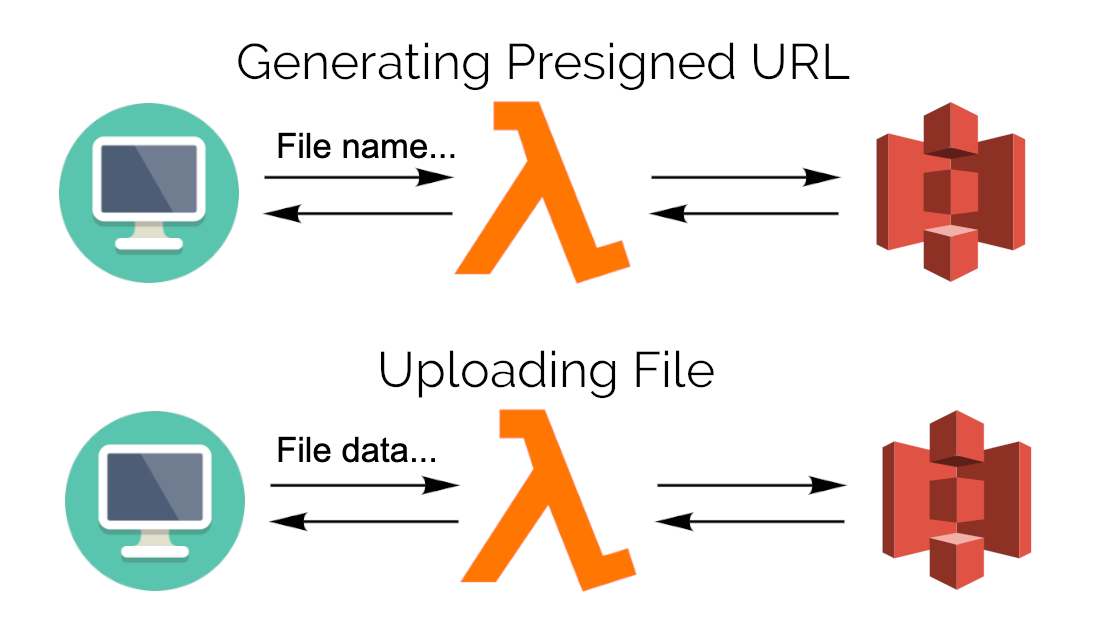
Let’s take a closer look. When we upload a file directly to the server, the server has to receive the file data and send the file data to S3. With the pre-signed url approach, we let the client side do it. So the server side can save twice the data size from receiving and uploading data.
5/ Demo
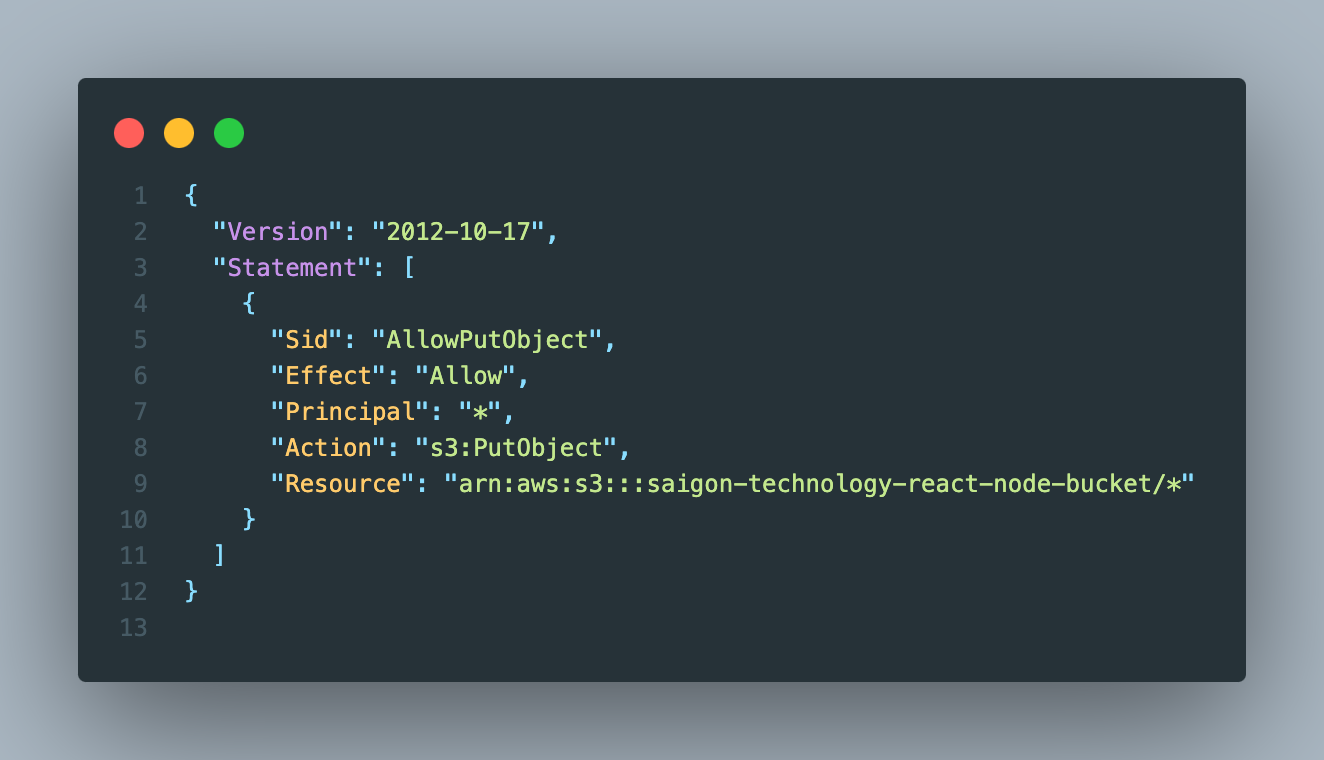
The first thing after you create a bucket is attach the bucket policy to it. My demo purpose is to upload a file to s3 bucket, that’s why I only need 1 statement of policy: put object.
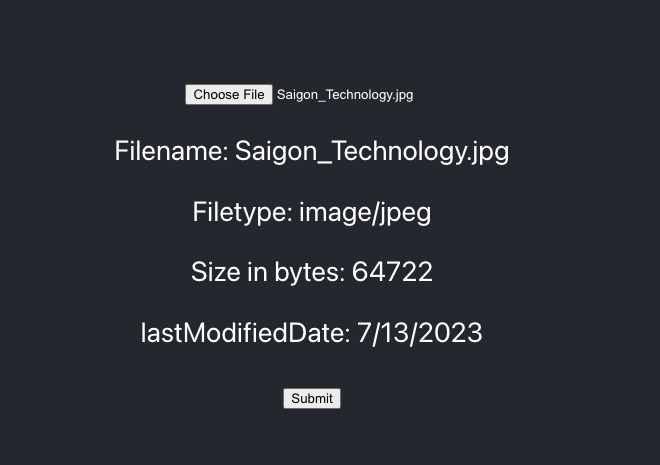
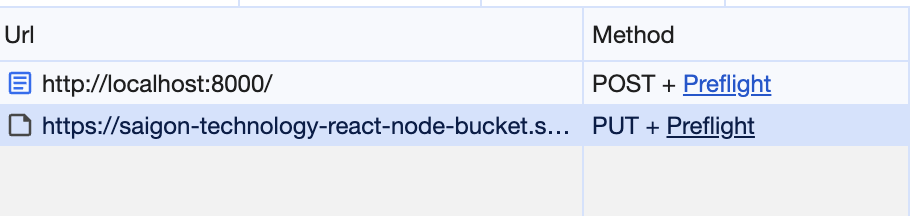
I want to upload a picture to S3 by clicking on the Submit button. This action will include 2 steps:
1/ Call to our server and tell it “Let’s give me an url to upload the image”.
2/ Use this url to upload the image.
Let’s see if my picture has been uploaded successfully to my bucket or not.
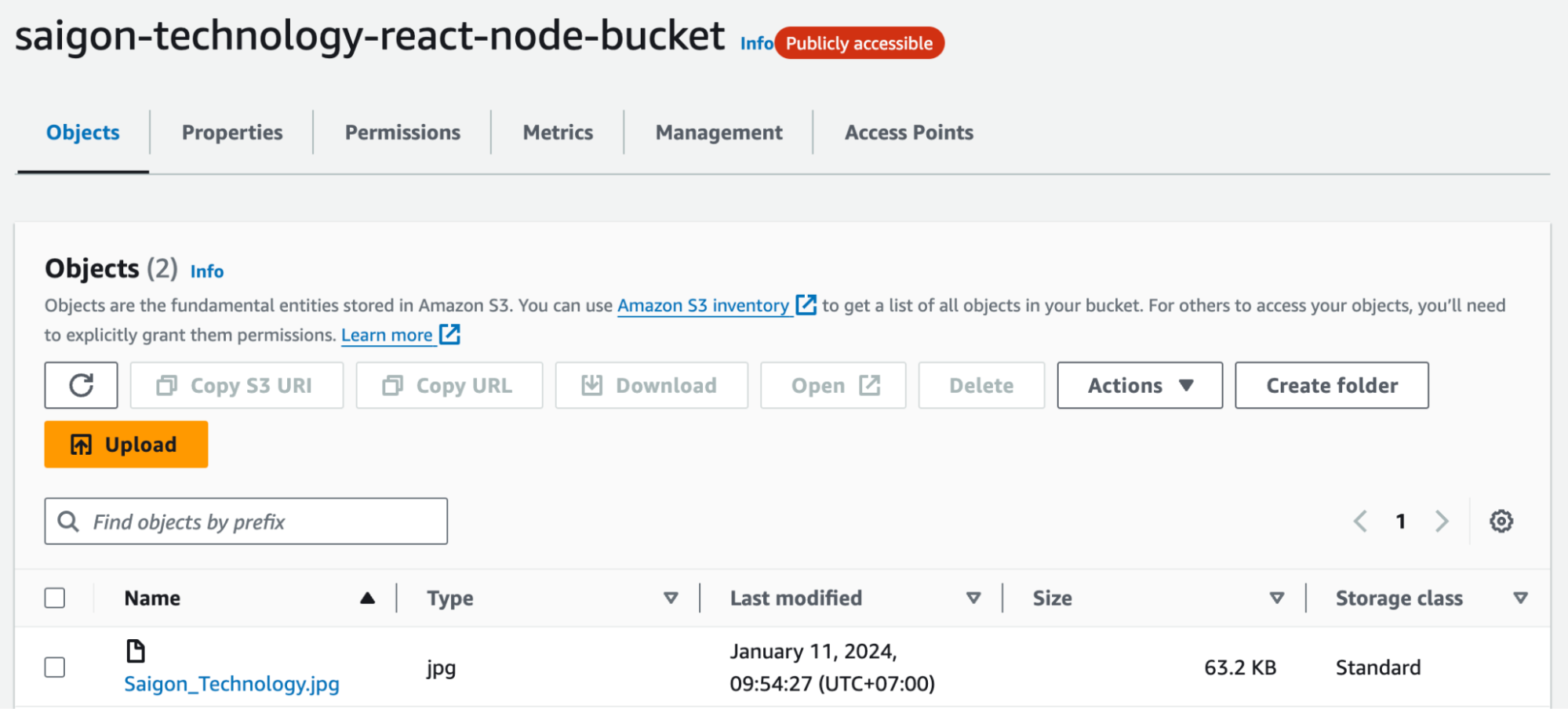 Congratulations. We have uploaded the first image to S3 using a pre-signed url in the most simple and cost effective way.
Congratulations. We have uploaded the first image to S3 using a pre-signed url in the most simple and cost effective way.
6/ Conclusion
Amazon S3 is a widely used object storage service offered by Amazon Web Services. It provides highly scalable and durable storage for various types of data.
- Scalability: S3 allows you to store and retrieve virtually unlimited amounts of data, scaling seamlessly as your storage needs grow. It automatically handles storage capacity management, ensuring high availability and performance.
- Durability and Reliability: S3 is designed to provide 99.999999999% (11 nines) durability, meaning your data is highly protected from loss. It achieves this by replicating data across multiple geographically distributed data centers, reducing the risk of data loss.
- Security: AWS S3 offers robust security features to protect your data. You can set access control policies, manage permissions, and use encryption mechanisms (server-side encryption, client-side encryption) to safeguard your data at rest and in transit.
- Cost-effective: S3 follows a pay-as-you-go pricing model, allowing you to pay only for the storage you use. It offers different storage classes with varying costs, such as Standard, Intelligent-Tiering, Glacier, etc., enabling you to optimize costs based on your data access patterns and retention requirements.
- Performance: S3 provides high throughput and low latency for data retrieval, allowing quick and efficient access to stored objects. It supports parallel object downloads, range retrieval, and CDN integration through AWS CloudFront, enhancing performance for global access.
Beside that there’s some disadvantages of using AWS S3:
- Data Transfer Costs: While data transfer within the same AWS region is usually free, transferring data between different AWS regions or outside of AWS can incur additional costs. If you have significant data transfer requirements, these costs should be considered.
- API Complexity: The S3 API can be complex to work with, especially for beginners. It requires a good understanding of the API documentation and best practices to make efficient use of the service. However, various SDKs and libraries are available to simplify development.
- Eventual Consistency: S3 provides eventual consistency for read-after-write consistency, which means that if you write an object, it may take a short time before all subsequent reads reflect the updated data. This may pose challenges in certain scenarios that require immediate consistency.
- Object Size Limitations: Although the maximum individual object size limit in S3 is quite large (up to 5 terabytes), it may still present limitations for certain use cases involving extremely large files.
- Steep Learning Curve: As with any cloud service, there can be a learning curve associated with configuring and managing AWS S3 effectively. Understanding the various features, storage classes, and access controls may require some initial effort.
Resources:
- Demo source code: Repo’s link
References:
– https://bobbyhadz.com/blog/aws-s3-presigned-url-react
– https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html

Web Application Development
Related articles

Hybrid App Development: A Practical Decision Guide for Businesses

Multi-Agent Systems: The Future of AI Collaboration

From Code to Cash: Introducing the Stripe API in payments

Building a Soccer Prediction DApp: A Complete Guide to Smart Contract Gaming

Exploring ECMAScript 2024: What’s New and Exciting?

Implement Producer/Consumer patterns using Channel in C#

Real-time ASP.NET with SignalR

Logging And Structured Logging With Serilog The Definitive Guide



{kind=link}
{kind=link}