An introduction about Graph Database – Gremlin

Introduction
Graph database is a database that uses nodes and edges with properties to represent the connections between objects in a data model. Nodes are entities or domain objects in the model. Edges are directional links between two nodes. Both nodes and edges have labels and properties to describe the
Graph databases are useful for scenarios where the connections between data are more important than the data itself. Some examples of graph database use cases are:
- Recommendation engines in e-commerce, social media, and content platforms. Graph databases can help provide personalized and relevant suggestions to users based on their preferences, behavior, and network.
- Fraud detection in banking, insurance, and cybersecurity. Graph databases can help identify fraud patterns and anomalies by analyzing the relationships between transactions, accounts, devices, and locations.
- Network and IT infrastructure monitoring for telecom, cloud, and IoT applications. Graph databases can help manage complex interdependencies between network components, devices, services, and users.
- Master data management for enterprises that need to organize and integrate data from multiple sources and systems. Graph databases can help create a unified view of data entities and their relationships across the organization.
- Knowledge graphs for search engines, digital assistants, and semantic web applications development. Graph databases can help store and query structured and unstructured data that represents facts, concepts, entities, and their relationships.
- These are just some of the use cases where graph databases can provide advantages over traditional relational or document databases. Graph databases can also be used for artificial intelligence, life sciences, government, social networks, identity and access management, and more.
When should we use a graph database?
- Hierarchical or interconnected data, entities, with multiple parents.
- Complex many-to-many relationships. One relation flexibly connects multiple entities.
- Examine interrelated data, generate new information from existing facts. Detect subtle connections.
What is the Gremlin?
Gremlin lets users write short and powerful traversals or queries on their property graph using a functional, data-flow language. A Gremlin traversal consists of a series of (possibly nested) steps that each do a single operation on the data stream.
Vertices and edges make up a property graph. Both objects can have properties that are key-value pairs of any number.
- Vertices/nodes: Vertices denote discrete entities.
- Edges/relationships: Edges denote relationships between vertices.
- Properties: Properties express information (or metadata) about the vertices and edges. There can be any number of properties in either vertices or edges, and they can be used to describe and filter the objects in a query.
- Label: A label is a name or the identifier of a vertex or an edge. Labels can group multiple vertices or edges such that all the vertices/edges in a group have a certain label.
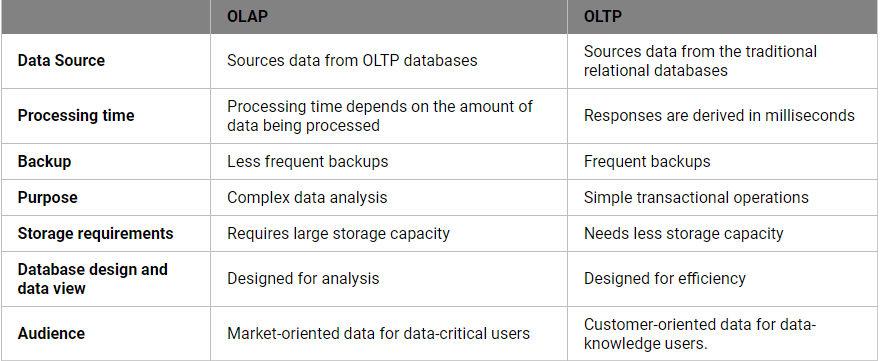
OLTP vs OLAP: What Are The Differences?
Online Transaction Processing or OLTP is a system that deals with transactions (inserts, updates, deletes) on data. It allows multiple people to perform different database transactions in real time over the internet. An OLTP system saves and stores transactional data in a database. OLTP databases include many records and fields that keep track of each transaction. These types of processing systems are useful for financial and non-financial transactions that we do daily, such as hotel reservations, in-store purchases, ATMs, text messaging, and password changes.
Online analytical processing or OLAP is a method of answering queries that have multiple dimensions of data. OLAP systems perform multidimensional analysis and reporting on large amounts of data. This system uses data from a central data store, a data mart, or an OLAP data warehouse. An OLAP cube is the key component of OLAP systems because it enables users to run queries, analyze and report on multidimensional data.
Why choose a Graph database?
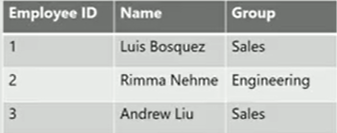
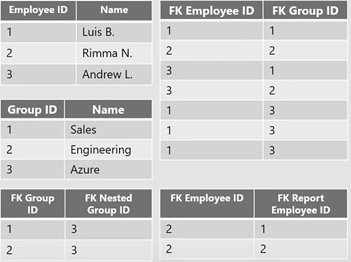
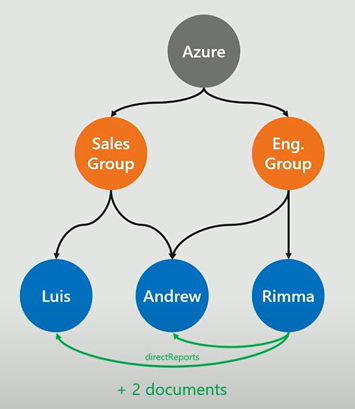
Walk through a quick example. We have a database with 2 groups sales and engineering and some employees.
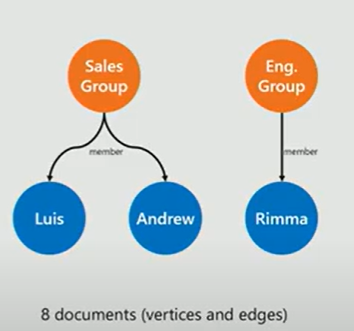
Adding a subgroup Azure that contains the sales and engineering group as its subgroups and connecting Andrew to the engineering group requires two relationship tables in the relational database: one table that relates employee and group, and one table that relates group and nested group.

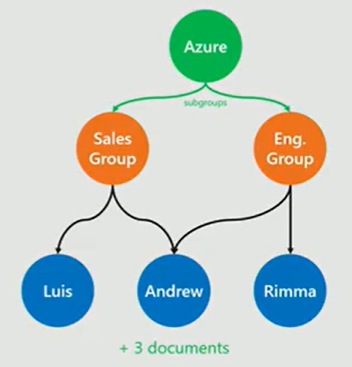
Reporting to Andrew and Luis is a requirement for Rimma. How does the database reflect this?
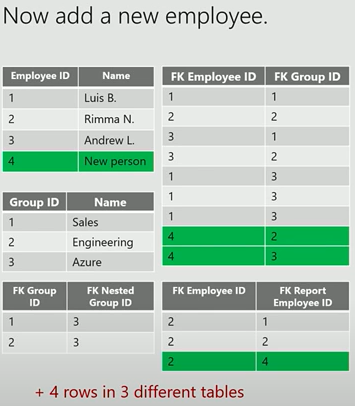
We need to change the RDM database to add a new employee who is in the engineering group and who manages Rimma: one row in the employee table, two rows in the relationship table between employee and group, and one row in the relationship Report Employee table. However, we only need to add one vertex with two edges in the graph database.
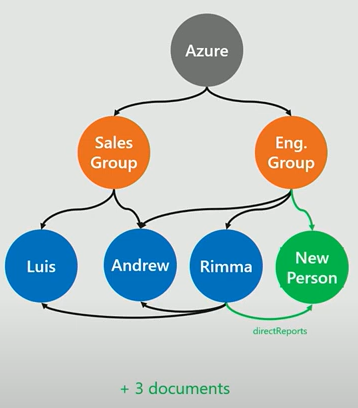
The last requirement can demonstrate the difference between RDM database and graph database when querying.
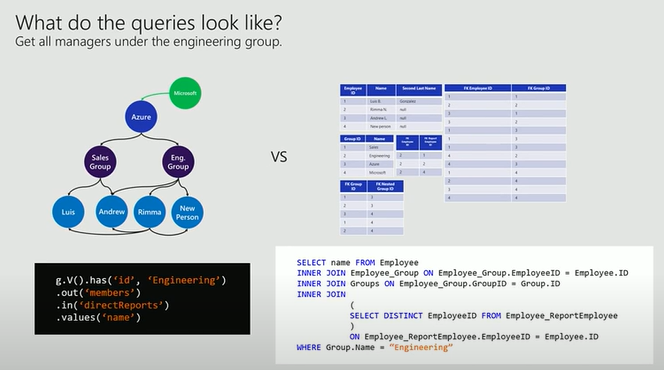
Through the example above, graph databases are also more resilient to changes in the data model, as they do not require migrations or updates to existing data. Addition to this, graph databases are faster and more efficient than relational databases when performing complex queries that involve traversing multiple relationships and graph databases can use index-free adjacency, which means that each node stores a pointer to its adjacent nodes, eliminating the need for costly joins. Relational databases are slower and more resource-intensive than graph databases when performing complex queries that involve multiple joins. Relational databases have to scan and join multiple tables, which increases the query time and memory usage.
Fundamental
Gremlin enables the users to execute complex queries to navigate their graphs by using a chained series of steps, with each step applying an operation on the data stream.
Every step is either a map-step (altering the objects in the stream), a filter-step (eliminating objects from the stream), or a sideEffect-step (calculating statistics about the stream).
- Map steps: transform the incoming traverser’s object to another object

- Filter steps: allow or disallow the traverser from proceeding to the next step.

- SideEffect steps: pass the object, but yield some side effect.

- Create the vertex or edge:
- g.addV(label).property(property1, value1).property(property2, value2)…property(propertyN, valueN)
- g.V(id).hasLabel(label).addE(labelE).to(g.V(label2)).property(property2, value2)…property(propertyN, valueN)
- Update a vertex or edge:
- g.V(id).property(property1, new value)
- g.E(id).property(property1, new value)
- Drop a vertex or edge:
- g.V(id).drop()
- g.E(id).drop()
- Clear all edges or vertices
- g.E().drop()
- g.V().drop()
- Common Serialization format
- Storing (converting) a graph as GraphML (XML) or GraphSON (JSON)
- graph.io(graphml()).writeGraph(‘my-graph.graphml’)
- graph.io(graphson()).writeGraph(“my-graph.json”)
- Reading a graph saved as GraphML (XML) or GraphSON (JSON)
- graph.io(IoCore.graphml()).readGraph(‘my-graph.graphml’)
- graph.io(IoCore.graphson()).readGraph(‘my-graph.json’)
- Storing (converting) a graph as GraphML (XML) or GraphSON (JSON)
- Timing a query
- using a timer step to calculate the time it takes to locate all vertices in the graph
- clock(1) {g.V().has(‘airport’,’country’,’CN’).next()}
- clock(100) {g.V().has(‘airport’,’country’,’CN’).next()}
- using a timer step to calculate the time it takes to locate all vertices in the graph
Gremlin With .NET
Install nuget package Gremlin.net.
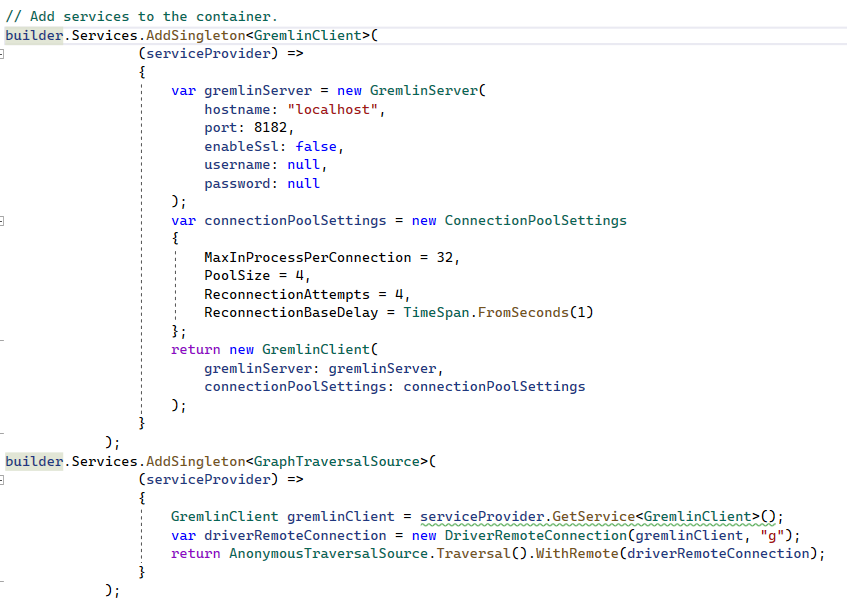
- Config service:
- CRUD in Gremlin .Net.
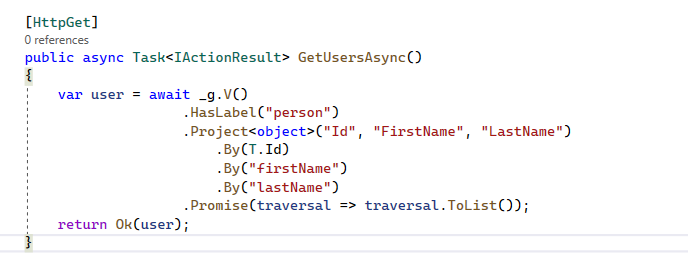
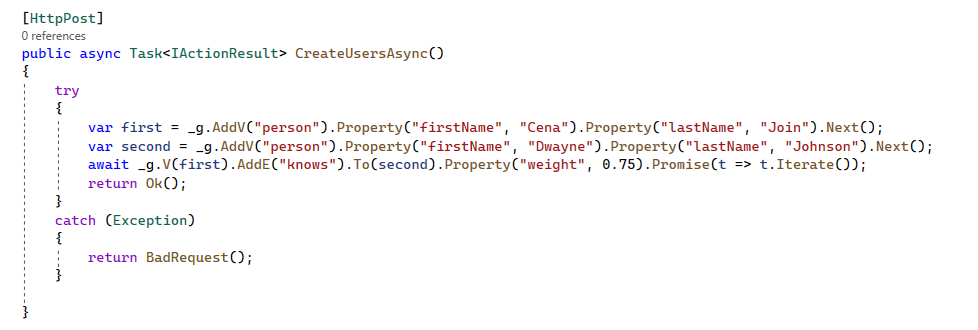

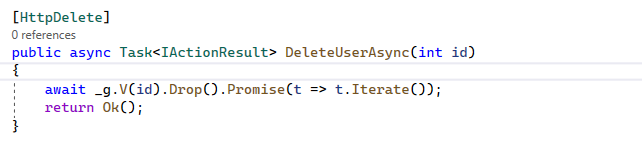
Demo: Basic Traversal Graph
The graph, air-routes is a model they built of the world airline route network that is fairly accurate. This file can be downloaded from github repository at the following URL: https://github.com/HoangVrian/GraphDatabase/tree/master/SampleData
The air-routes graph consists of several vertex types that are indicated using labels. The most frequent ones being airports and countries. Connections between airports are represented as edges
type: the vertex/node type. Will be ‘airport’ for airport vertices
code: the code of airport like FRA or IST
icao: the ICAO code or none.
desc: the text description of the airport
region: the geographical region like US-TX or GB-ENG
runways: the number of available runways
longest: the length of the longest runway in feet
elev: the elevation in feet above sea level
country : the country code such as AU or CA.
city: The name of the town the airport is located in
lat : the latitude of the airport
lon : the longitude of the airport
In this blog, I will make some demo common steps in gremlin with this example Graph. Let’s start.
- Create a new TinkerGraph instance and establish a graph traversal source object by calling the new graph’s traversal method as follows.
graph = TinkerFactory.createModern()
g = traversal().withEmbedded(graph)
- Load air-routes.graphml to init your graph.
graph.io(graphml()).readGraph(‘/app/air-routes.graphml’)
- Query:
- // Find vertices that are airports
g.V().hasLabel(‘airport’)
- // Find the DFW vertex
g.V().has(‘code’,’DFW’)
- //Retrieving property values from a vertex
g.V().has(‘airport’,’code’,’DFW’).values()
- Count.
- // How many airports are there in the graph?
g.V().hasLabel(‘airport’).count()
- // How many routes are there?
g.V().hasLabel(‘airport’).outE(‘route’).count()
- // How many of each type of vertex are there?
g.V().label().groupCount()
- Limit Data Returned
- // Only return the FIRST 20 results
g.V().hasLabel(‘airport’).values(‘code’).limit(20)
- // Only return the LAST 20 results
g.V().hasLabel(‘airport’).values(‘code’).tail(20)
- // Return the first two airport vertices found
g.V().hasLabel(‘airport’).range(0,2)
- Remove Duplicate
- // before removing duplicates
g.V().has(‘region’,’GB-ENG’).values(‘runways’).fold()
- // after removing duplicates
g.V().has(‘region’,’GB-ENG’).values(‘runways’).dedup().fold()
- Using List, Set
- // Create a list with number of runways in Texas
list = g.V().has(‘airport’,’region’,’US-TX’).
values(‘runways’, ‘code’).toList().join(‘,’)
– // Create a set of number of runways in Texas (no duplicates)
setr = g.V().has(‘airport’,’region’,’US-TX’).
values(‘runways’).toSet().join(‘,’)
- Working with numerical operations
- // How many routes are there from Austin?
g.V().has(“airport”,”code”,”AUS”).out().count()
- // Sum of values – total runways of all airports
g.V().hasLabel(‘airport’).values(‘runways’).sum()
- // Statistical mean (average) value – average number of runways per airport
g.V().hasLabel(‘airport’).values(‘runways’).mean()
- //maximum value – longest runway
g.V().hasLabel(‘airport’).values(‘longest’).max()
- Working predicate value
- // Airports with fewer than 4 runways
g.V().has(‘runways’,lt(4)).values(‘code’,’runways’).fold()
- // How many airports have 4 runways?
g.V().has(‘runways’,eq(4)).count()
- // How many airports have anything but just 2 runway?
g.V().has(‘runways’,neq(2)).count()
- // Airports with greater than 2 but fewer than 4 runways.
g.V().has(‘runways’,inside(2,4)).values(‘code’,’runways’)
- Using where to filter data
- // Find airports with more than three runways
g.V().where(values(‘runways’).is(gt(3)))
- // Airports with more than 70 unique routes from them
g.V().hasLabel(‘airport’).where(out(‘route’).count().is(gt(70))).count()
- Using option to write Case/Switch
- // Choose and option can help you generate a query that looks like a case statement
g.V().hasLabel(‘airport’).
choose(values(‘code’)).
option(‘DFW’,values(‘desc’)).
option(‘AUS’,values(‘region’)).
option(‘LAX’,values(‘runways’))
- Using choose to write if…then..else
- // If an airport has a runway > 14,000 feet return its code else return its description
g.V().has(‘region’,’US-TX’).
choose(values(‘longest’).is(gt(14000)),
values(‘code’),
values(‘desc’)).
limit(5)
- Using repeat…until for looping
– // What are some of the ways to travel from LHR to FRA?
g.V().has(‘code’,’LHR’).
repeat(out().simplePath()).
until(has(‘code’,’FRA’)).
path().by(‘code’).limit(10)
Summary
Graph databases are a powerful way to store and query data that is highly connected and complex. They offer advantages over traditional relational databases in terms of scalability, flexibility, performance, and expressiveness. By using a graph traversal language like Gremlin, you can easily explore and manipulate your graph data in various ways.
Thank you for reading this blog. I hope you have learned something about graph databases and the Gremlin language and how they can be used in your projects. I also have a fun challenge for you based on the air-routes graph. Can you find the shortest path from the country with code ‘AUS’ to the country with code ‘AGR’ with only 4 stops? If you can, please send your query to me (Link) and I will check your answer.
Follow our newsletter. Master every day with deep insights into software development from the experts at Saigon Technology!

Back-end Development Services
Related articles

Java or .NET For Web Application Development

What You Need to Know about State Management: 6 Techniques for ASP.NET Core MVC

Unlocking the Potential of .NET MAUI for Frontend and Web Developers
")
Build Customer Service (.NET, Minimal API, and PostgreSQL)

Say Hello to .NET MAUI

How to build UI with .NET MAUI


