
Overview
Data lake and data warehouse are two important concepts in the field of data and analytics. A data warehouse is used to store and manage structured data that is optimized for analysis and reporting purposes. On the other hand, DataLake is used to store data in all forms, including structured and unstructured data, for various purposes such as data analysis, data processing, and machine learning. DataLake allows for the real-time storage and processing of large amounts of data at a lower cost than a data warehouse. However, to use the data in a DataLake, users need to have knowledge of data processing and data science.

Data Lake and Data Warehouse General Usage
Understanding About Data Lake
What is a Data Lake?
Data Lake is a large storage system with the ability to store complex and different data in terms of format, size, and source. It is a concept of big data that allows for efficient and flexible storage and management of data from many different sources. The data in a data lake is usually not pre-processed and can be accessed and processed by many different tools, allowing users to easily and quickly access data for analysis and the extraction of important information. The main purpose of a data lake is to help organizations build a strong and flexible data analytics platform while enhancing their ability to analyze and manage data.
There are two main activities of the data lake: storage and operations.
Data Lake Storage and Operations
- Data Lake Storage
Data Lake Storage is a data repository that allows you to store raw data in its native format. It is designed to handle massive amounts of structured, semi-structured, and unstructured data and provides the flexibility to store data from a variety of sources, such as sensors, social media, websites, and databases. Data lakes are used by organizations to store and analyze large volumes of data, including structured data from relational databases and unstructured data such as social media posts, videos, and audio.
- Data Lake Operations
Data Lake Operations refer to the management of a data lake, including its maintenance, security, and performance optimization. This involves the creation, organization, and management of data in a data lake. The operations include defining data schemas, setting up access controls, monitoring data quality, and optimizing data retrieval and analysis. In addition, data lake operations also involve data backup and recovery, data archiving, and the implementation of data retention policies.
Some common tools used for data lake storage and operations include Hadoop Distributed File System (HDFS), Amazon S3, Azure Data Lake Storage, Google Cloud Storage, Apache Spark, and Apache Hive. These tools provide the ability to store and process large amounts of data and perform complex data analysis tasks.
Data lake storage and operations are essential components of modern data management and analytics strategies, enabling organizations to store, process, and analyze large volumes of data from a variety of sources.
Features of Data Lake
A data lake is a large and centralized repository of raw data that allows organizations to store and manage vast amounts of structured, semi-structured, and unstructured data at scale.
Some of the key features of a data lake include:
- Scalability: Data lakes are designed to be highly scalable, which means they can accommodate massive amounts of data with ease. They can be easily expanded to accommodate the growing volume of data without the need for significant changes to the underlying architecture.
- Flexibility: Data lakes are flexible in terms of data types and sources. They can accommodate structured, semi-structured, and unstructured data from various sources, including databases, social media, and sensors.
- Raw data storage: Data lakes store data in its raw form without any pre-processing or schema imposition. This allows data scientists and analysts to perform their own data transformation and analysis, without being limited by pre-defined schemas or structures.
- Cost-effectiveness: Data lakes are typically built using inexpensive storage and computing resources, such as commodity hardware, cloud storage, and open-source software. The cost-effectiveness of a data lake also depends on the benefits it provides to the organization. If a data lake can provide valuable insights that can help drive business decisions, it can be more cost-effective in the long run.
- Data governance: Data lakes provide robust data governance capabilities to ensure data quality, security, and compliance with data privacy regulations. These include features such as data lineage, data cataloging, data access controls, and auditing.
- Data governance: Data lakes provide robust data governance capabilities to ensure data quality, security, and compliance with data privacy regulations. These include features such as data lineage, data cataloging, data access controls, and auditing.
When should we use Data Lake?
Data lakes are often used in situations where there is a need to store large volumes of data that may be coming from a variety of sources and in different formats.
Here are some common scenarios that you should consider using a data lake:
- Big Data Analytics: If you are working with large volumes of data and need to perform complex analytics on that data, a data lake can be a good choice. Data lakes can handle massive amounts of data and support a wide range of analytics tools and techniques.
- Data Integration: Data lakes can be used to integrate data from different sources, such as social media, IoT devices, and other data sources. This can help you create a single, unified view of your data.
- Data Exploration: Data lakes allow users to explore data in a flexible and agile manner. Since the data is stored in its raw form, users can experiment with different data models and schemas without having to worry about data loss or schema changes.
- Machine Learning: Data lakes can be a good choice for storing large volumes of data used for machine learning models. This can include both structured and unstructured data, and the data can be easily accessed by machine learning algorithms.
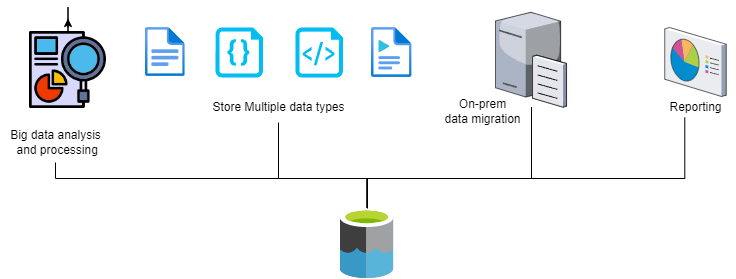
Data Lake Common Use Cases
Understanding About Data Warehouse
What is a Data Warehouse?
Data warehouse is a storage system designed to support the processes of analysis and decision-making in organizations. It is built to store the historical and current data of an organization from many different sources. The data in a data warehouse is typically pre-processed to ensure consistency and accuracy. Query and data analysis tools are integrated with the data warehouse to serve the data analysis needs of the organization. Data warehouses are typically designed with an object-oriented data structure and optimized to increase data retrieval speed and analysis performance. The main purpose of a data warehouse is to provide managers and executives with easy and quick access to detailed and overall information about the organization’s operations.
Data Warehouse Storage and Operations
- Data Warehouse Storage
Data warehouse stores historical data over a long period of time, so it typically uses a lot of storage space. The storage infrastructure must be able to handle the large volumes of data and provide fast access to the data. The data is typically stored in a multi-dimensional format, with organized data by subject, time, and other relevant dimensions.
- Data Warehouse Operations
Data warehouse operations are responsible for maintaining and managing the data warehouse environment. This includes tasks such as data loading, data transformation, data cleansing, and data integration. The goal is to ensure that the data is accurate, consistent, and up-to-date.
Data warehouse operations also include monitoring the system’s performance, optimizing queries and database design, and ensuring data security and compliance. Overall, effective data warehouse storage and operations are essential for organizations that rely on data-driven insights to make critical business decisions.
Here are some common techniques for data warehouse storage and operations:
- Dimensional modeling: This is a technique that involves organizing data into fact tables and dimension tables. Fact tables contain the measures or metrics that you want to analyze, and dimension tables contain the attributes that provide context for the measures. This approach makes it easier to analyze the data and helps improve query performance.
- Data Partitioning: This involves dividing data into smaller, manageable parts called “partitions.” Partitioning can help improve query performance by reducing the amount of data that needs to be scanned for each query.
- Compression: Data compression techniques can help reduce the amount of storage space required for data. This can be especially useful for historical data that is accessed less frequently.
- Indexing: Indexes can help speed up queries by allowing the database to quickly locate the data that is needed for a query. Indexing should be used judiciously, as too many indexes can slow down data loads and updates.
- Backup and recovery: It is important to have a solid backup and recovery strategy in place to protect against data loss. This can involve regularly backing up the data warehouse to a separate storage location and having a plan in place for restoring data in case of a disaster.
Effective data warehouse storage and operations involve a combination of techniques such as dimensional modeling, partitioning, compression, indexing, backup and recovery, and monitoring and optimization. By applying these techniques, you can build a robust data warehouse that can support complex.
Features of Data Warehouse
Data warehouse is a large, centralized repository of data that is used for analytical purposes. It is designed to support business intelligence and decision-making activities by providing a single source of truth for data from multiple sources. Some of the key features of a data warehouse include:
- Integrated: Data warehouses integrate data from various sources into a unified and consistent format. This allows users to access and analyze data from different departments, systems, and databases.
- Subject-Oriented: Data warehouse is organized around specific subject areas, such as sales, customers, or inventory. This enables users to focus on the data they need for their particular area of interest or expertise.
- Historical: Data warehouse stores historical data over a period of time, providing a detailed record of past events and trends. This is important for trend analysis, forecasting, and decision-making.
- Non-Volatile: Data in a data warehouse is non-volatile, meaning that it is not updated or deleted once it is stored. This ensures that historical data is preserved and can be compared with current data.
- Time-Variant: Data warehouses are time-variant, meaning that they can store data from different points in time. This allows users to analyze changes in data over time, track trends, and identify patterns.
- Aggregated: Data warehouse often contains summarized data, aggregated across various dimensions such as time, geography, and product categories. This helps speed up queries and analysis and provides a high-level view of data.
When should we use Data Warehouse?
Data warehouses are typically used in scenarios where an organization needs to store and analyze large amounts of structured data from multiple sources. They are particularly useful for businesses that require consistent and reliable data for decision-making, such as in the finance, retail, and healthcare industries. Data warehouses are optimized for querying and reporting, making it easier to perform complex analyses on historical data.
Here are some scenarios when it is appropriate to use a data warehouse:
- Consolidate data from multiple sources: If you have data stored in different systems, such as transactional databases, CRM systems, and social media platforms.
A centralized data repository, such as a data warehouse, enables the consolidation of disparate data sources into a single location.
- Analyze historical data: A data warehouse is designed to store historical data over a long period of time. This enables organizations to analyze trends and make informed decisions based on past performance.
- Perform complex queries: Data warehouses are optimized for querying large datasets, allowing users to perform complex queries and generate reports quickly.
- Support business intelligence and analytics: Data warehouses are typically used to support business intelligence and analytics applications, providing users with a comprehensive view of their data and enabling them to make informed decisions.

Data Warehouse Use Case
Difference between Data Lake and Data Warehouse
Data lakes and data warehouses are both data management systems, but there are some key differences between them.
|
Area |
Data Warehouse |
Data Lake |
|
Data storage |
Data warehouses store structured data in a highly organized and pre-defined schema |
Data lakes store unstructured or semi-structured data in its native format without a pre-defined schema. |
|
Data processing |
Data warehouses are designed for processing and analyzing structured data |
Data lakes are designed for processing and analyzing both structured and unstructured data. |
|
Data processing time |
Data warehouses have a slower data processing time, as the data must be transformed and structured before it can be analyzed |
Data lakes have a faster data processing time, as the data can be analyzed in its native format without the need for transformation |
|
Data accessibility |
Data warehouses are highly organized and optimized for querying and reporting, making it easy to access data quickly |
Data lakes are less organized, making it more difficult to access data quickly without advanced analytics tools. |
|
Data governance |
Data warehouses have strict governance and control processes, ensuring that data is secure and compliant with regulations |
Data lakes have looser governance processes, making it easier to store and analyze data without extensive oversight. |
Data warehouses are best suited for structured data that requires a highly organized schema and strict governance processes, while data lakes are best suited for unstructured or semi-structured data that requires flexibility in data processing and analysis.
Case study
To see how data lakes and data warehouses are applied, we will go through the very simple case study below:
Requirement: The retail company ABC generates vast amounts of data from various sources, such as point-of-sale (POS) systems, e-commerce platforms, customer service interactions, and social media channels. They need to analyze this data to gain insights into customer behavior, inventory management, and sales performance to make data-driven decisions.
Solution to Approach:
- Data Storage: the ABC company creates a data lake that can handle different types of data, including structured, semi-structured, and unstructured data. The data lake is used to store all the raw data in its original format, which makes it easier to perform data exploration and analysis later on.
- Execute ETL: Next, the company sets up a data warehouse and uses ETL tools to extract and transform the relevant data from the data lake into a structured format (ETL). The data warehouse is optimized for querying and reporting, and it provides a single source of truth for the company’s sales and marketing teams.
- Data Analytics: With the data warehouse in place, the company can use BI tools and advanced analytics to analyze customer behavior data and gain insights into their preferences and needs. For example, they can identify patterns in purchasing behavior, track the effectiveness of marketing campaigns, and segment customers based on their demographics and interests.
The use of a data lake and data warehouse enables the retail company to store and analyze large volumes of data efficiently and effectively. By leveraging these tools, the company can gain valuable insights into customer behavior and use that knowledge to improve its business strategies and drive growth.
Conclusion
In conclusion, both data lakes and data warehouses serve as crucial components of modern data architecture. While data warehouses are best suited for structured data and well-defined queries, data lakes can handle unstructured and semi-structured data with flexible querying capabilities. Data warehouses provide a single source of truth, whereas data lakes offer a centralized location for storing raw data, making it easier to access and analyze. Ultimately, the choice between a data lake and a data warehouse depends on the organization’s specific data needs and resources.
By selecting the right solution, organizations can ensure that they have the necessary tools to manage their data effectively and gain valuable insights to drive their business forward.
Resources
- Demo source code: N/A
References

Hire Software Developers
Related articles

The Differences Between DataOps and DevOps in Software Development

Big Data: Why Hire an External Big Data Team

An introduction about Graph Database – Gremlin

Introduction to TPL Dataflow in C#
