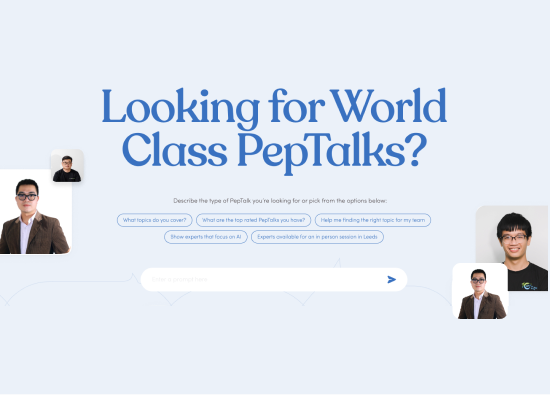






Analyze The Object On Image Using Computer Vision Technologies
With the help of Computer Vision techniques, this effort seeks to create a system that can evaluate the Object on Image.
Detail