Harnessing the Power of Elasticsearch: boosting your search capabilities

This article provides an insightful examination of Elasticsearch as a dynamic search engine. It highlights the system’s proficiency in managing extensive data and improving search functions across various applications. This comprehensive overview is ideal for those looking to deepen their understanding of Elasticsearch’s capabilities. For more details, the full article is available here.
1. Introduction:
Elasticsearch is a distributed search engine that is built on top of the Apache Lucene library. It scales horizontally as more data is added, making it a highly flexible and scalable platform. It is an open-source technology that is designed to handle large volumes of data, making it an ideal choice for companies that need to analyze vast amounts of information.
Kibana is an open-source data visualization and exploration tool used to analyze and visualize data stored in Elasticsearch. It provides a user-friendly interface to create real-time dashboards, charts, and graphs to visualize and analyze complex data. Kibana is often used in conjunction with Elasticsearch and Logstash to form the ELK stack (Elasticsearch, Logstash, Kibana).
Key features of Elasticsearch:
– Handle structured and unstructured data.
– Its powerful search capabilities: perform complex search queries on large volumes of data in near-real-time.
– Log analysis: ingest and index log data from servers, applications, and other systems in near-real-time.
2. Key concepts
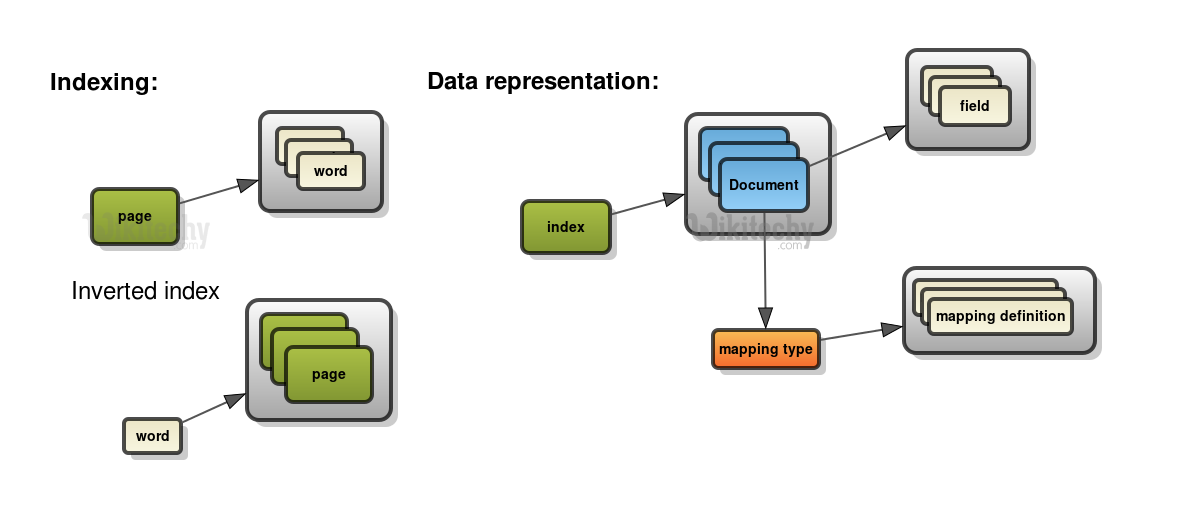
There are 8 key concepts of Elasticsearch that we need to understand
- Documents: stores data as documents, which can be thought of as rows in a database table.
- Indices: A collection of documents that have similar characteristics, such as data type or purpose.
- Shards: Elasticsearch breaks indices into smaller pieces called shards, which can be distributed across multiple nodes in a cluster.
- Replicas: Elasticsearch creates replicas of shards to provide redundancy and fault tolerance.
- Nodes: Elasticsearch operates as a distributed system, with each node in the cluster performing a specific function.
- Mapping: Elasticsearch uses mapping to define how data is indexed and searched.
- Queries: Elasticsearch provides a powerful querying system that allows for complex searches.
- Aggregations: Aggregations allow for data analysis and reporting, allowing users to extract insights from their data.
In this blog, I want to introduce the usage of Elasticsearch with Python using the library Python Elasticsearch Client. Beside that, I use Kibana as a monitoring tool for Elasticsearch clusters.
3. Installation
This topic uses Python version 3.
– Install Elasticsearch through this link. Start Elasticsearch on port 9200 by default
– Install Kibana through this link. Start Kibana on port 5600 by default
– Install Python Elasticsearch Client by following this link
4. Implementation
– Once we have installed the Python Elasticsearch Client, the first thing we need to do is connect to Elasticsearch. We can do this using the Elasticsearch() class.
import json
from urllib.request import Request, urlopen
from elasticsearch import Elasticsearch, exceptions
# connect to Elasticsearch
es = Elasticsearch([{“host”: “localhost”, “port”: 9200}])
– Create an index to store the documents in data structures mapping with the data type of fields. You can define a mapping type, which determines how the document will be indexed and fields in your data. Each index has one mapping type.
For example:
mappings = {
“properties”: {
“abilities”: {
“properties”: {
“ability”: {
“properties”: {
“name”: {
“type”: “text”,
“fields”: {
“keyword”: {
“type”: “keyword”,
“ignore_above”: 256,
}
},
},
“url”: {
“type”: “text”,
“fields”: {
“keyword”: {
“type”: “keyword”,
“ignore_above”: 256,
}
},
},
}
},
“is_hidden”: {“type”: “boolean”},
“slot”: {“type”: “long”},
}
},
“base_experience”: {“type”: “long”},
}}
This mapping based on data structure that we’re using. Example mapping above for data at https://pokeapi.co/api/v2/pokemon/1/.
Then create index:
es.indices.create(index=“pokemon_index”, mappings=mappings)
If no mapping type is defined, Elasticsearch will automatically detect mapping type and add fields, which is called dynamic mapping.
es.indices.create(index=“pokemon_index”)
– Load data and start indexing. After that, we can perform action search with custom query corresponding to query types.
# pokemon json data
url = “https://pokeapi.co/api/v2/pokemon/1/”
req = Request(url=url, headers={“User-Agent”: “Mozilla/5.0”})
# Decode the bytes to string, assuming the remote file is encoded in UTF-8
decoded_data = urlopen(req).read().decode(“utf-8”)
# Parse the JSON data into object
data = json.loads(decoded_data)
# indexing data
es.index(index=“pokemon_index”, id=1, document=data)
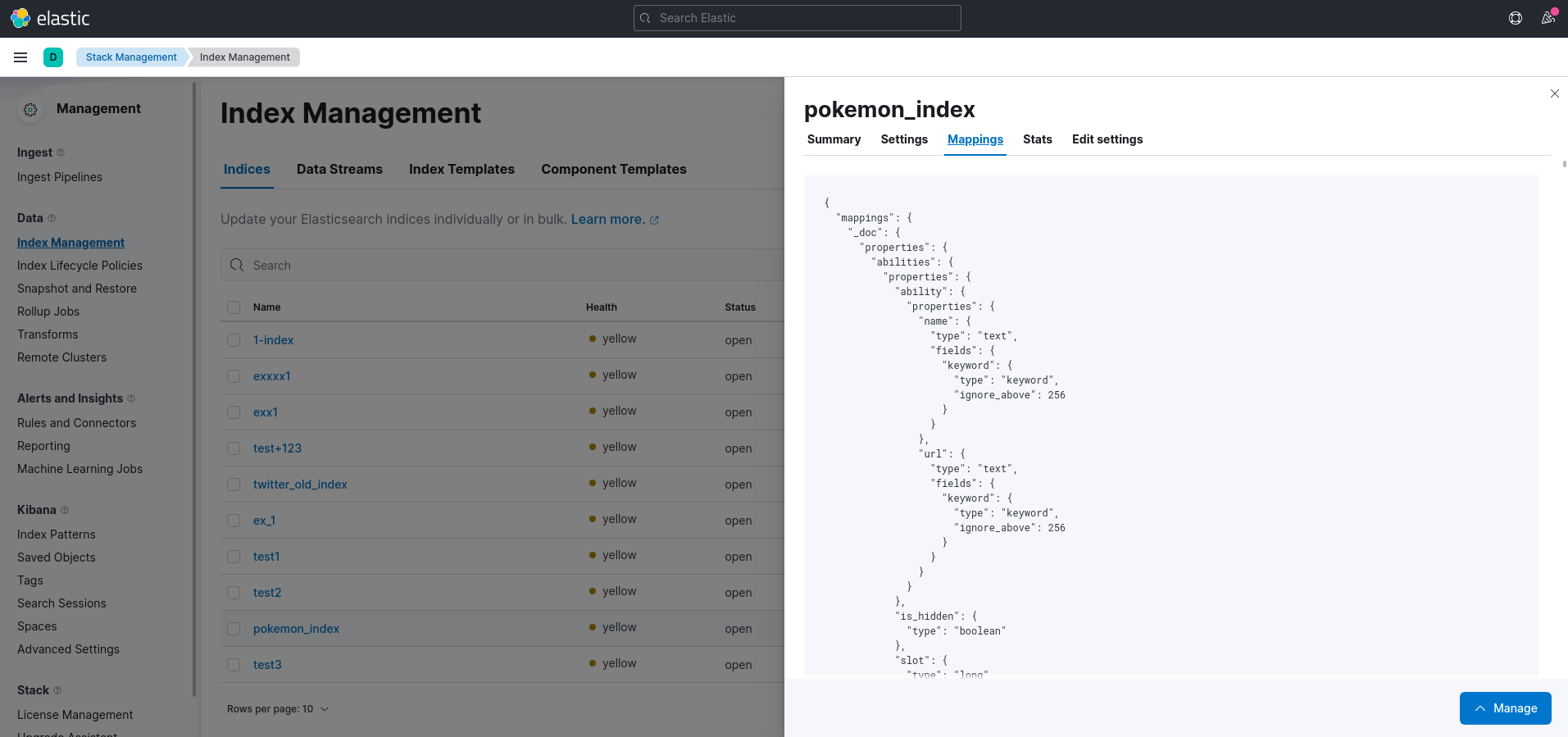
– Access Kibana on port 5600 with url: `/app/management/data/index_management/` to check indices list and mapping on each indices. This is mapping for data https://pokeapi.co/api/v2/pokemon/1/ that used above.
– Now is when we perform action search using many types of query. You can find Query DSL (Domain Specific Language) here.
- Leaf query clauses: look for a particular value in a particular field. For example: match query, term query, range query
- Compound query clauses: combine multiple queries in a logical fashion (bool, dis_max)
- Allow expensive queries:
a) Using the Elasticsearch Python library:
- Let’s try with the simple search through the “match” query which matches documents containing the searched term in any field.
query = {
{
“_source”: [“name”, “height”, “weight”],
“size”: 1,
“query”: {“match”: {“name”: “bulbasaur”}},
}
}
result = es.search(index=“pokemon_index”, body=query)
# result
# {
# “took”: 5,
# “timed_out”: False,
# “_shards”: {“total”: 1, “successful”: 1, “skipped”: 0, “failed”: 0},
# “hits”: {
# “total”: {“value”: 1, “relation”: “eq”},
# “max_score”: 0.2876821,
# “hits”: [
# {
# “_index”: “pokemon_index”,
# “_type”: “_doc”,
# “_id”: “1”,
# “_score”: 0.2876821,
# “_source”: {“name”: “bulbasaur”, “weight”: 69, “height”: 7},
# }
# ],
# },
# }
- _source: specify fields should be included in the search results
- size: limit number of results returned
b) Use Kibana DevTools:
- Navigate to the DevTools tab
- Enter search query in the console and perform search action
5. Conclusion
Thanks for reading and scrolling here. This blog is just an introduction about the simple usage of Elasticsearch. There are many deeper things related to Elasticsearch if you want to harness more power of it. Based on it, you can improve your search functionality and provide your users with better search results. This is a valuable asset for any organization looking to improve its search capabilities. Whether you’re working with a small data set or a massive one, Elasticsearch can help you harness the power of your data and get the most out of your search efforts.
If you have any questions, feel free to let me know via email: quang.ngdb@saigontechnology.com
Have a good day!
References
- https://www.elastic.co/guide/index.html
- https://elasticsearch-py.readthedocs.io/en/v8.7.0/
- https://www.elastic.co/guide/en/kibana/current/install.html
Follow our newsletter. Master every day with deep insights into software development from the experts at Saigon Technology!

AI Development Services
Related articles

The Difference Between AI Software And Traditional Software Business

The Differences Between AI and ML

The Innovation of Computer Vision with AI and ML

