Database Transaction And How To Handle It In NodeJS With Prisma

1/ What is Database Transaction?
Database Transaction is a unit of work, which may include many actions we want to perform with the database system. In a simple word, the transaction represents any change of the database.
The main purpose of transaction is:
- Furnish a dependable operational entity capable of facilitating accurate recovery and preserving database consistency in the event of system failure.
- Provide isolation between programs and allow concurrent access to the database.
2/ Transaction basic and ACID properties
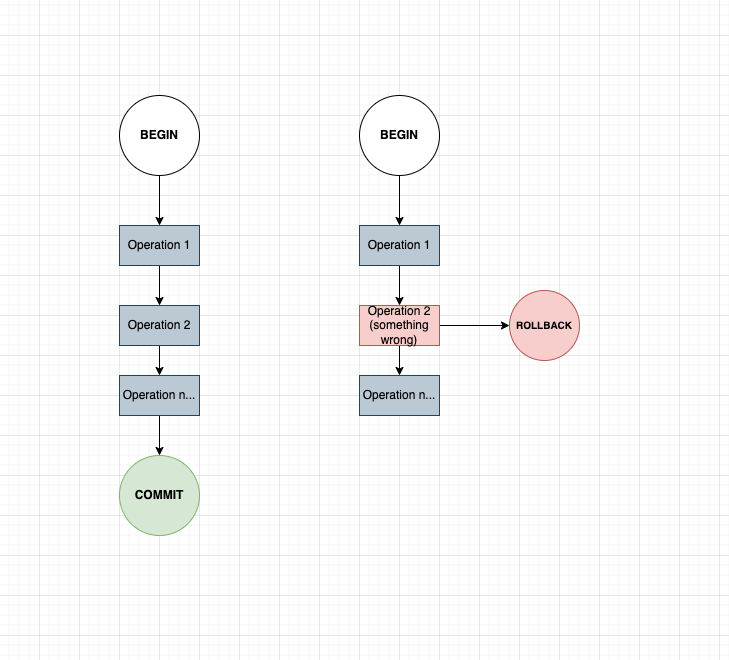
Each transaction can have a single operation or a set of operations, which will be performed sequentially. Transaction will wrap this set and using the following pattern to handle SQL execution:
- Begin the transaction.
- Perform a series of data manipulations and/or queries.
- If executed without encountering errors, commit the transaction.
- However, if an error arises during the process, roll back the transaction to its initial state.
By following this pattern, the database can make sure it will provide the ACID properties, which will be intended to guarantee data validity despite errors, power failures, and other mishaps.
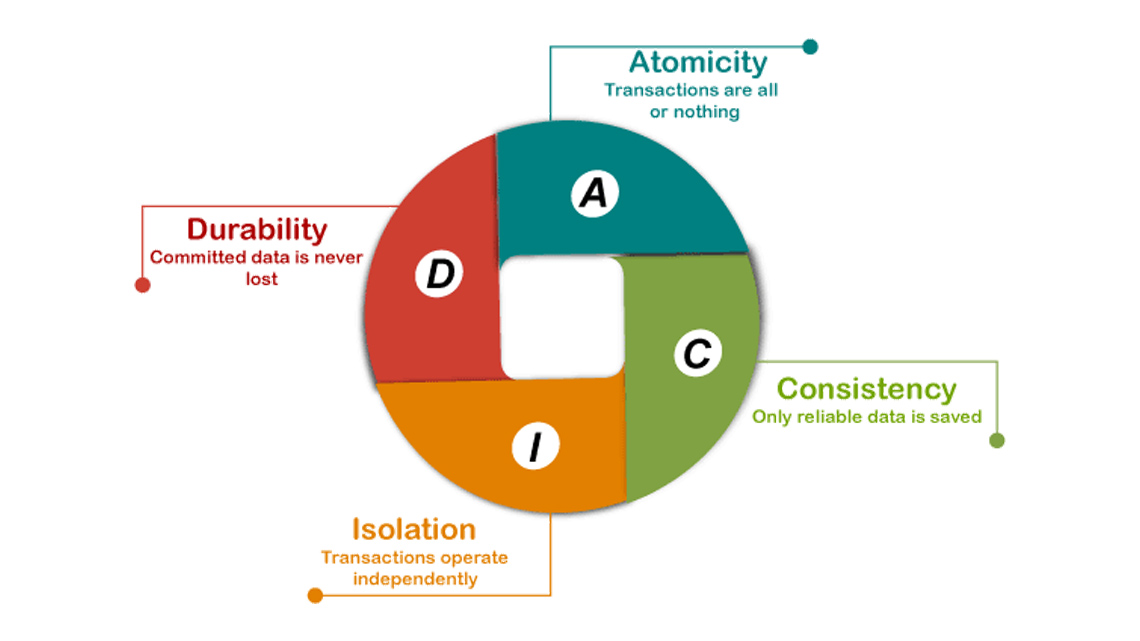
2.1/ Atomicity
Atomicity ensures that every transaction is viewed as a singular “unit,” ensuring it either completes entirely or fails entirely. In a simple word, it means all or nothing. All the statements (operations) in one transaction must either succeed or fail.
Consider a monetary transfer from bank account A to account B as an illustration of an atomic transaction. This process entails two distinct operations: withdrawing funds from account A and depositing them into account B. To maintain consistency, it’s imperative that we don’t observe the deduction from account A until we’re confident that the corresponding credit has been made to account B. By executing these actions within an atomic transaction, we ensure that the database preserves its integrity. In the event of failure in either operation, the database remains consistent, preventing any debits or credits from occurring.
2.2/ Consistent
Consistency guarantees that a transaction transitions the database from one coherent state to another, upholding database invariants. This means that any data modifications adhering to defined rules, such as constraints, cascades, triggers, and their combinations, must maintain validity. In essence, consistency ensures that the database remains in a reliable and predictable state after each transaction, preventing the introduction of invalid or contradictory data.
CREATE TABLE IF NOT EXISTS acid_test (A INTEGER, B INTEGER, CHECK (A + B = 100));
Let’s imagine we have a table with a validation requirement check that A+B = 100.
Suppose a transaction attempts to deduct 10 from A without updating B. Given that consistency checks occur after each transaction, it’s established that A + B equals 100 before the transaction initiation. While the deduction from A may succeed, ensuring atomicity, a subsequent validation check reveals A + B now equals 90, violating the database’s rules. Consequently, the entire transaction must be aborted, and the affected rows rolled back to their pre-transaction state to maintain consistency.
2.3/ Isolation
If our system only executes one transaction by one, everything will be simple.
Transactions are frequently executed concurrently, necessitating isolation to ensure that concurrent transaction execution results in the same database state as if the transactions were executed sequentially. Isolation serves as the primary objective of concurrency control, guaranteeing that each transaction’s effects on the database remain isolated from those of concurrently executing transactions. This isolation prevents interference or inconsistency between transactions, maintaining data integrity and consistency across the database.
Consider two transactions:
- T1 transfers 10 from A to B.
- T2 transfers 20 from B to A.
Combined, there are four actions:
- T1 subtracts 10 from A.
- T1 adds 10 to B.
- T2 subtracts 20 from B.
- T2 adds 20 to A.
If isolation is maintained, these operations are performed in order.
But if isolation is not maintained, the order of operations might be messed up. One of the possibility might be:
- T1 subtracts 10 from A.
- T2 subtracts 20 from B.
- T2 adds 20 to A.
- T1 adds 10 to B.
Consider if T1 fails, but T2 already modified data so it cannot restore data before T1.
Depending on the isolation level used, the effects of an incomplete transaction might not be visible to other transactions, which we will deep dive into in another section of this article.
2.4/ Durability
Durability ensures that once a transaction has been successfully committed, its changes are permanently saved and will persist even in the event of a system failure, such as a power outage or crash. This means that once a transaction is confirmed as complete, its effects on the database are guaranteed to endure and will not be lost due to unexpected system failures.
3/ Concurrently control mechanism
There are many mechanisms to ensure that transactions are executed reliably, maintaining data integrity and allowing multiple transactions to work concurrently while still preserving consistency like concurrency control mechanisms, transaction logging, and buffer management. In this section, I will talk about concurrent control mechanisms and how it works.
Executing transactions sequentially can indeed lead to increased waiting times for other transactions, potentially causing delays in overall execution. To enhance system throughput and efficiency, multiple transactions are executed concurrently. Concurrency control plays a crucial role in database management systems (DBMS) by facilitating simultaneous data manipulation or execution by multiple processes or users without compromising data consistency. By carefully coordinating the concurrent execution of transactions, concurrency control mechanisms ensure that data remains consistent and that transactions do not interfere with each other’s operations, thereby optimizing system performance and resource utilization.
There are some commonly used concurrency control mechanisms: Lock-based concurrency control, Timestamp-based concurrency control, Multi-version concurrency control (MVCC), Optimistic concurrency control, Two-phase locking (2PL), Snapshot isolation. But the most popular method to be used to handle concurrent control is Lock-based and MVCC.
3.1/ Lock-based
This mechanism involves acquiring and releasing locks on database objects such as tables, rows, or columns to control access by concurrent transactions.

Type of locks
There are different types of locks, including shared locks (read locks) and exclusive locks (write locks), which help prevent conflicting operations:
- Share locks: Allows multiple transactions to read the data item concurrently but prevents any transaction from modifying it until all shared locks are released.
- Exclusive locks: Grants exclusive access to a data item, preventing other transactions from reading or writing it until the lock is released. Once a process acquires a lock on a resource, other processes attempting to acquire the same lock must wait.
Multiple shared locks can be held simultaneously on a resource. However, if a resource is already locked with a shared lock, another process can’t acquire an exclusive lock. Likewise, a process can’t acquire a shared lock on a resource that’s exclusively locked.
Locking problems
Although locking is a good way to handle concurrent access, it still has some issues. Three most problems of locking is:
- Fails to release the lock: What if the lock fails to release? It will block other transactions and the whole process will be blocked.
- Lock contentions: Some resources may be accessed frequently and multiple transactions could try to acquire locks on these resources at the same time. It leads to subsequent transactions may encounter delays while waiting for others to complete, resulting in contention for these resources or locks. Imagine you are in a line waiting to check out but there is only 1 counter.
- Locking deadlock: one transaction locks resource A and tries to access the lock on resource B before releasing the lock on the first resource. Simultaneously, another process acquires the lock on resource B while attempting to acquire the lock on resource A. Consequently, both processes remain incomplete until they obtain these locks.
3.2/ MVCC
An alternative approach to locking is multiversion concurrency control (MVCC), where the database offers each reading transaction the original, unaltered version of data being modified by another active transaction. This enables readers to function without requiring locks, meaning writing transactions don’t impede reading transactions, and vice versa.
Isolation and its problems
Remember that the results of the transaction are only visible after a commit to the database happens so what happens when a transaction tries to read a row updated by another transaction? Now our application can handle multiple concurrent actions at the same time, that’s why we will be faced with more complex problems.
Most of our operations are READ and that’s why most of the problem is about read phenomena.
We have 4 commons read phenomena includes:
- Dirty read: Occurs when a transaction reads data modified by another concurrent transaction that has not yet been committed. This can lead to reading inconsistent or erroneous data.
- Nonrepeatable read: Happens when a transaction re-reads data it has previously retrieved and finds that the data has been altered by another transaction that has since been committed. This inconsistency may cause unexpected behavior.
- Phantom read: Occurs when a transaction re-executes a query with a search condition and finds that the set of rows satisfying the condition has changed due to another transaction being committed in the meantime. This can lead to inconsistencies in query results.
- Serialization anomaly: Refers to a situation where the outcome of executing a group of transactions together is different from the result obtained by executing the same transactions sequentially, one after the other. This inconsistency can violate the desired consistency of the database.
Isolation levels
With the special problems of reading data when operating with multiple concurrent operations, our database system needs to implement different levels of isolation to solve problems for different use cases.
- Read uncommitted: The lowest isolation level, allowing transactions to read data that hasn’t been committed by other transactions. This level doesn’t provide isolation, meaning that concurrent transactions may see uncommitted data, potentially leading to inconsistent or incorrect results.
- Read committed:This level allows transactions to read only committed data, preventing dirty reads. However, it doesn’t address non-repeatable or phantom reads, as it doesn’t lock data during read operations. This is the default isolation level in PostgreSQL.
- Read committed: Transactions at this level lock resources throughout the transaction, preventing other transactions from modifying the same data. While it helps against non-repeatable reads, it may still encounter phantom reads. This level is often used to maintain consistency in data-intensive operations.
- Serializable: The highest level of isolation, emulating serial execution of transactions. All concurrent transactions are treated as if they were executed one after the other, ensuring the highest level of consistency and preventing all concurrency-related anomalies, including non-repeatable reads and phantom reads.
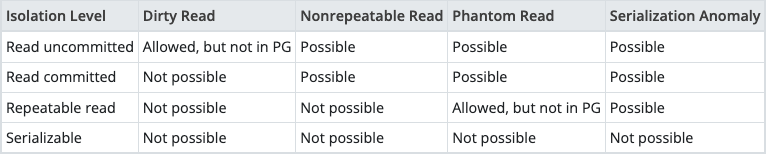
Although read uncommitted is the lowest isolation level. Some modern relational database systems like PostgreSQL do not allow it to happen in their system.
4/ Demo
One of the most valuable characteristics of isolation with developers is Atomicity. When you have to implement an API with a ton of operations including read, write, update and once an operation fails, others fail and immediately rollback data to the previous state to make sure our database system is consistent. Remember to use database transactions in this case.
My simple demo will help you to know how you can use transactions with NodeJS and Prisma: wrap all your operations with Prisma inside the transaction. In my code, assume my application is an application that only allows users to add money to their account with a specific money source: MOMO and VPBANK. My scenario is to create a transaction to add money from “MOMO” source, which is not allowed in our system.
Please check my code for more details.
5/ Conclusion
In conclusion, transactions are a vital aspect of database management systems, providing a mechanism for ensuring data integrity, consistency, and reliability. By grouping database operations into atomic units, transactions allow for the execution of multiple operations as a single, indivisible entity. This ensures that either all operations succeed and are committed to the database, or none of them are executed, maintaining data integrity and preventing partial updates.
Choosing a higher isolation level usually comes with a performance trade-off due to increased locking or versioning mechanisms to maintain consistency. The choice of isolation level depends on the specific requirements of your application, balancing the need for data consistency with the desired level of concurrency.
Resources:
- Demo source code: Repo’s link
References:
– https://medium.com/inspiredbrilliance/what-are-database-locks-1aff9117c290
– https://www.postgresql.org/docs/current/transaction-iso.html

Node.JS Development Services
Related articles

How to Setup CI/CD with CircleCI and Deploy Your NodeJS Project to a Remote Server

Go vs. Node.js: The Programming Language and a Runtime Environment Differences

The Pros and the Cons of Node.js Web App Programming: Everything You Need to Know
.webp "The Essential Guide to Clean Code Practices for JavaScript, React, and Node.js Projects")
