Lessons Learned Using AWS Services Part 1

1. Introduction
Welcome, everyone. When I first started working with AWS services, I brought over five years of experience as a Frontend Developer and some knowledge of Backend from online tutorials and articles. However, I had never truly delved into AWS services. Since graduating, the dream of becoming a Fullstack Developer has always driven me, but various reasons delayed my real-world Backend experience until recently. Persistence and a proactive approach to seeking opportunities, asking for Backend tasks in each project, finally led me to my first encounter with Backend and AWS.
In this post, I aim not only to share the challenges I faced while working with AWS services but also to offer specific solutions that helped me overcome them. I understand many young FE developers also dream of becoming Fullstack, and I hope my experiences will save you time and effort and help you avoid similar mistakes.
2. Overview of project architecture
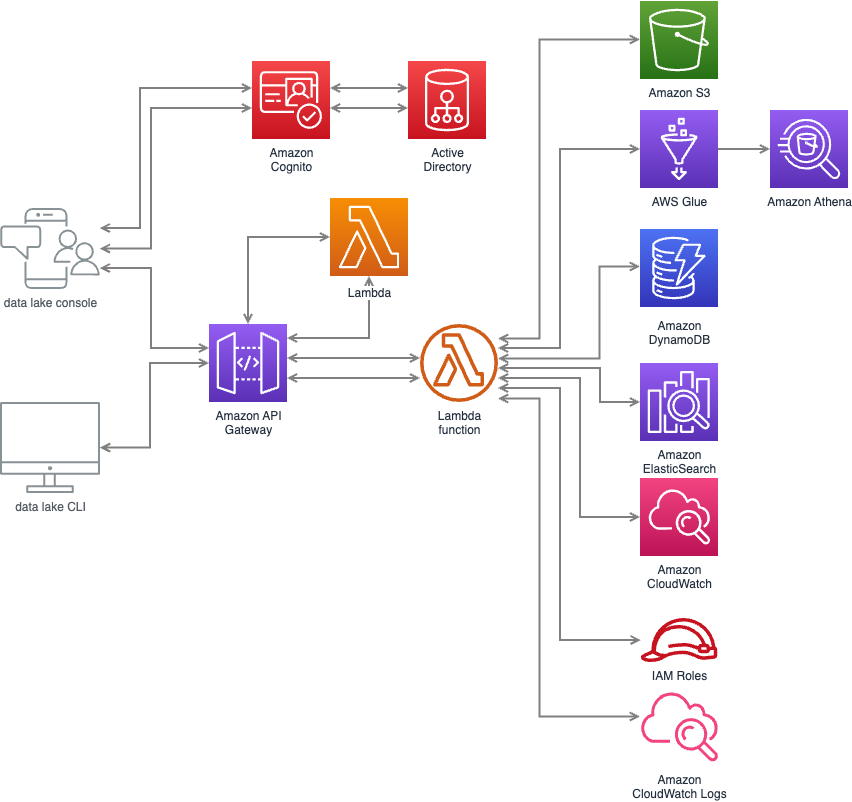
Pic 2.1: architecture overview
Our project’s architecture is intricate, but I’ll focus on the AWS components for clarity. We utilize AWS CodeCommit for version control of our source code. Upon code submission, AWS triggers events that activate CodeBuild and CodeDeploy processes. Our web application resides on AWS S3 and is served to users through AWS CloudFront. On the server side, we deploy our application logic onto Lambda functions. The API Gateway acts as the traffic controller, directing user requests to the corresponding Lambdas. These requests might involve various operations, such as querying RDS, accessing S3, or triggering SNS for notifications. To round it off, we employ CloudWatch for monitoring our resources and logging activities.
3. Lessons Learned 1: Each AWS service comes with its own set of limitations.
In the early stages of our project, my first task was to retrieve data from the History table and return data to frontend (FE) to display a table with pagination functionality. This prompted the question: should pagination be implemented by the FE or the backend (BE)? After consulting with several individuals, here are their responses. The FE developers proposed that it should be a task for the BE, whereas the BE team believed that the FE could manage it. The project manager (PM) suggested that whoever had fewer tasks should handle it. Who do you think would be the most suitable person to carry out that task?
Initially, our team leader preferred to offload all data processing to the FE, regardless of the data volume. Following the principle that ‘the customer is the king’ (our leader was on the client’s side), my thought was to keep the client happy, so why propose a BE solution and justify it when it could potentially displease the client? So, I followed the leader’s solution. However, this approach led to an unexpected lesson when our API started throwing errors. After reviewing the logs, we discovered that Lambda has a payload size limit. Luckily, the error occurred only with test data and was unlikely to happen in production, so no immediate action was required. This experience taught me an important lesson: when designing pagination solutions, especially with Lambda, we must consider the limitations on the payload size that can be returned.
There are numerous approaches to implementing pagination on the backend. However, delving into each method extensively within this article would warrant a separate discussion. Hence, rather than providing detailed steps here, I will provide a link to another blog post for those who need it.
4. Lessons Learned 2: Multiple approaches exist for achieving a single task
My second task was to store user-uploaded files. The common approach for upload features is to have a place on the FE for users to select their files, which are then sent to the BE, where the BE handles the file and stores it appropriately. While implementing this, I didn’t give it much thought; I just did what I thought was right and got to work. However, after the product was in use for a while, I received user feedback that they couldn’t upload files larger than 10MB. The reason was the API Gateway’s payload limit.
This led me to spend a lot of time considering different solutions and agonizing over whether to rebuild from scratch or modify what was already there. In hindsight, I realized my mistake was not spending enough time initially thinking about the solutions to choose the most suitable method before starting the implementation. I thought I was saving time on the task, but in reality, the time spent thinking about solutions to fix the issue might have been much more if I had taken the time to find the right solution from the beginning.
Nevertheless, we didn’t need to make any changes because, within the domain of our project, the documents weren’t too large, so there weren’t many cases of uploading large files. However, if I could go back to when we started building the feature, I would implement it based on the pre-signed URL feature. The advantage of this feature is that it allows users to directly upload documents to the S3 bucket without going through an intermediary server step. A colleague of mine has shared details on how to implement this, which you can refer to in another post here.
Additionally, during the feature implementation, I encountered an issue that was quite perplexing due to its elusive cause. Imagine a function that works perfectly in the local environment and passes initial tests in the staging environment, but then suddenly stops working. If you ever face an error where files can’t be opened after being uploaded to S3 or any other location while using the common method involving API Gateway and Lambda, I suggest checking the following questions to troubleshoot:
1. Question 1: Did you enable binary support for API gateway?
In the API Gateway, each API call carries a payload that could be either text or binary in nature. A text payload typically consists of a JSON string encoded in UTF-8 format. On the other hand, a binary payload encompasses all non-text data types, such as JPEG images, GZip compressed files, or XML documents. The setup necessary to handle binary media types within your API is contingent upon the integration approach—whether it’s a proxy or a non-proxy setup.
2. Question 2: Did you set up correctly Binary Media Type? Examples:
- image/png: Represents PNG image files.
- application/octet-stream: A generic binary data type.
- application/pdf: For PDF files.
- audio/mpeg: For MP3 audio files.
- video/mp4: For MP4 video files.
3. Question 3: Has the format of the request payload matched the input requirements of the BE yet? If not, have you configured the content handling?
If the answer to questions 1 and 2 is no, you can do the following:
Method 1: Enabling binary support using the API Gateway console
- Choose an existing API.
- Under the selected API in the primary navigation panel, choose **API settings**.
- In the **API settings** pane, choose **Manage media types** in the **Binary Media Types** section.
- Choose **Add binary media type**.
- Enter a required media type, for example, **multipart/form-data**, in the input text field. If additional media types are necessary, simply repeat the process to include them. For comprehensive binary media type support, use the wildcard /*.
- Choose Save changes.
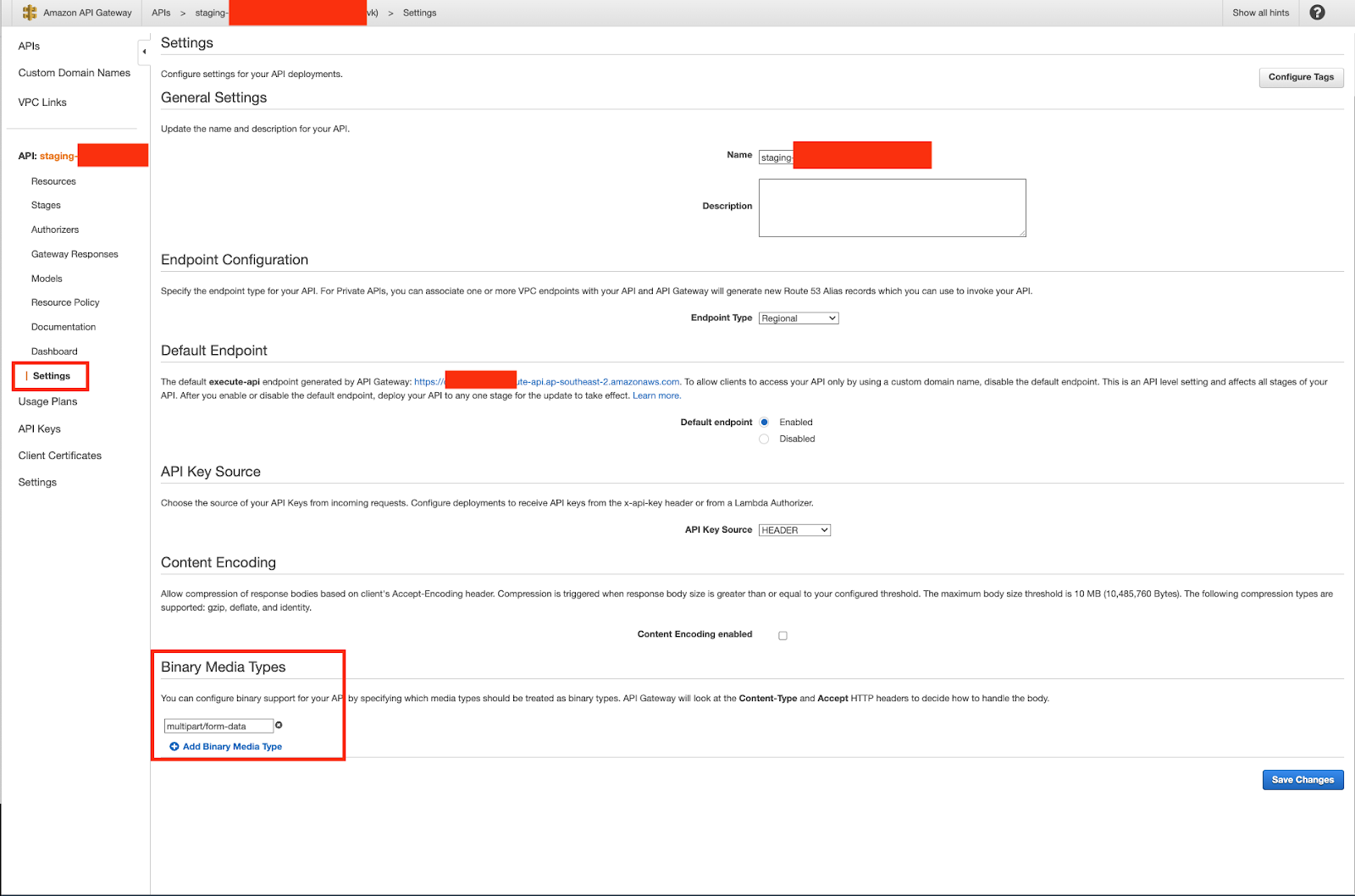
Pic 4.1: API settings example
Method 2: Using serverless.yml
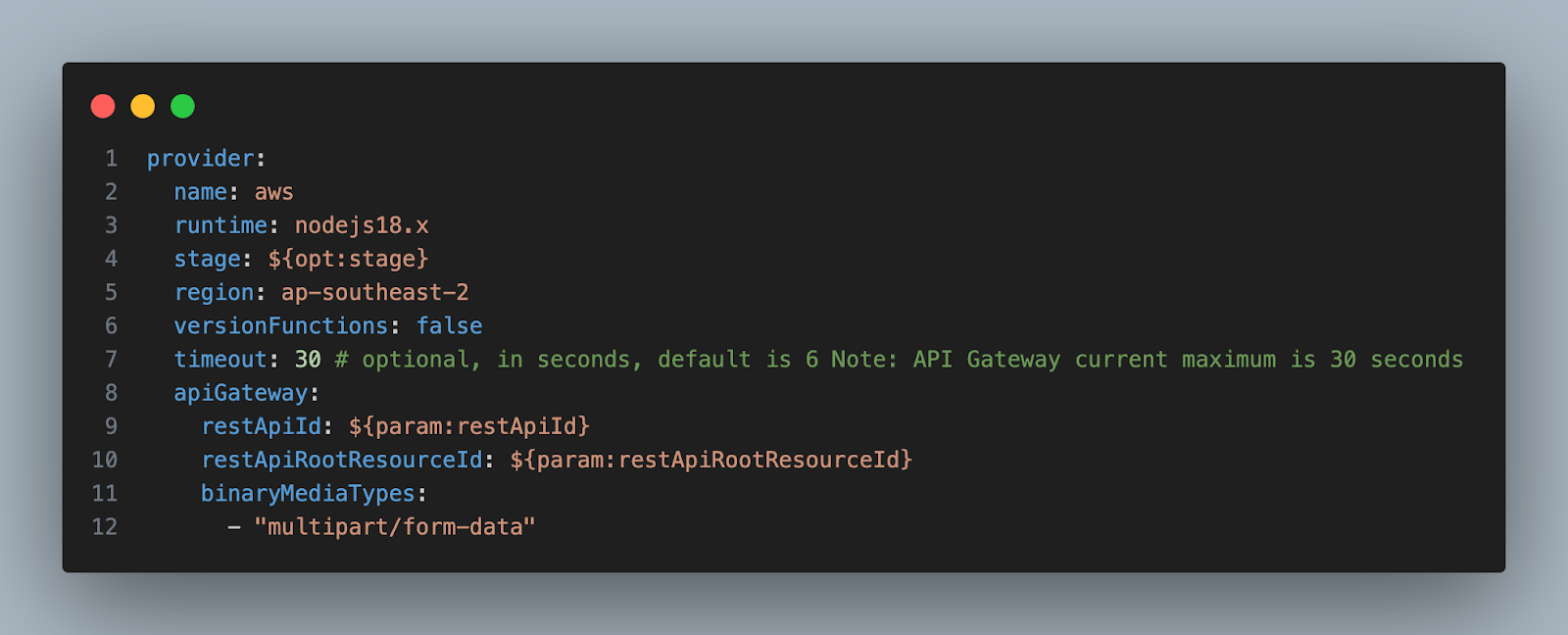
Pic 4.2: serverless.yml example
If the answer to question 3 is no, you can do the following:
Method 1: Using API Gateway console
1. Initiate a new resource or select one that’s already established within the API. For this example, we use the `/{folder}/{item}` resource.
2. Either establish a new method or utilize an existing one for the resource. For instance, consider the GET /{folder}/{item} method, which is configured to correspond with the Object GET action in Amazon S3.
3. For Content handling, choose an option.
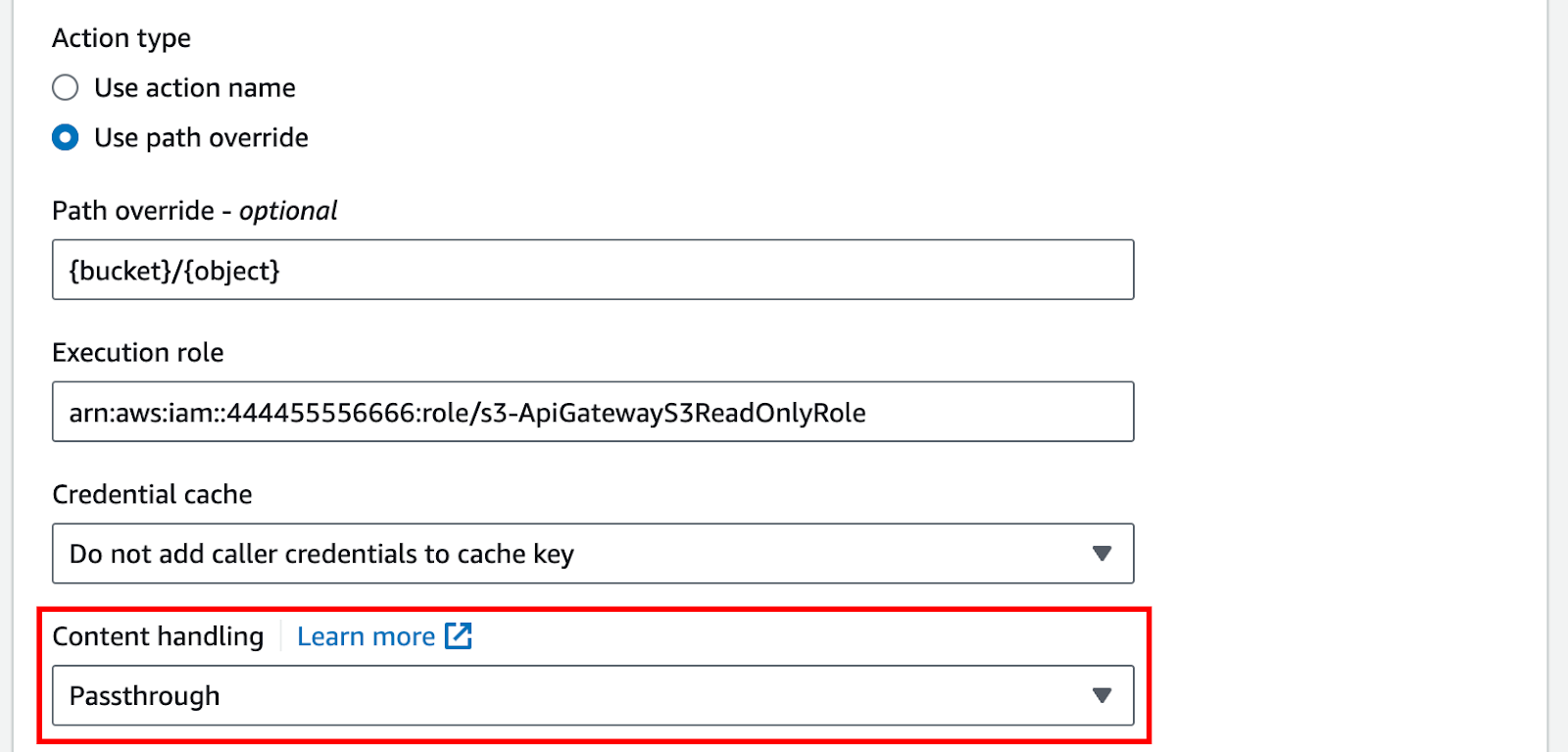
Pic 4.3: set up content handling via console. Source: AWS
Select Passthrough when no conversion is needed and both client and backend agree on the binary format. Opt for Convert to text to change a binary body into a base64-encoded string, useful when the backend expects a binary payload within a JSON property. Conversely, use Convert to binary if you need to revert a base64-encoded string back to its original binary form, either because the backend demands it, or the client can only process binary output.
4. For Request body passthrough, opt for When there are no templates defined (recommended) to allow the request body to pass through as is. Alternatively, selecting Never means the API will only accept data with defined content-types and reject all others lacking a mapping template.
5. Maintain the original Accept header from the incoming request in the integration request. This is particularly important if contentHandling is set to passthrough but you need to override this setting during runtime.
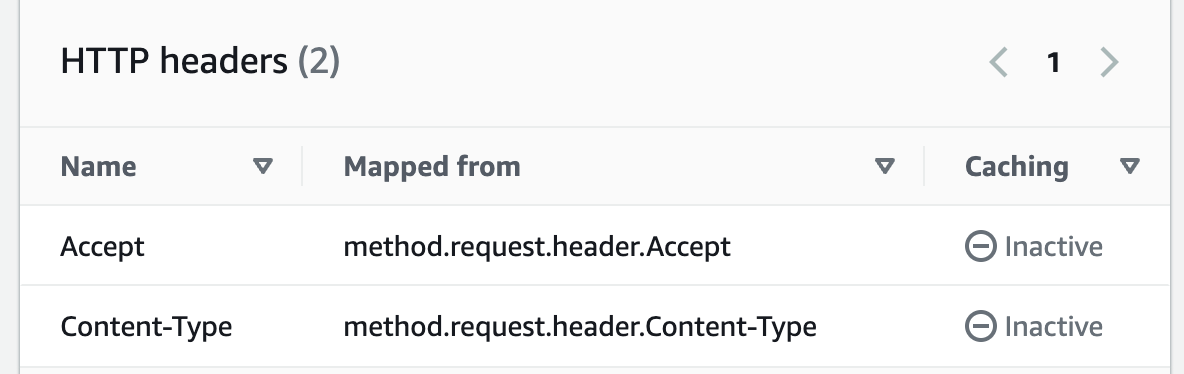
Pic 4.4: set up headers. Source: AWS
6. For convert to text, define a mapping template to put the base64-encoded binary data into the required format. Below is a sample mapping template designed for convert to text:
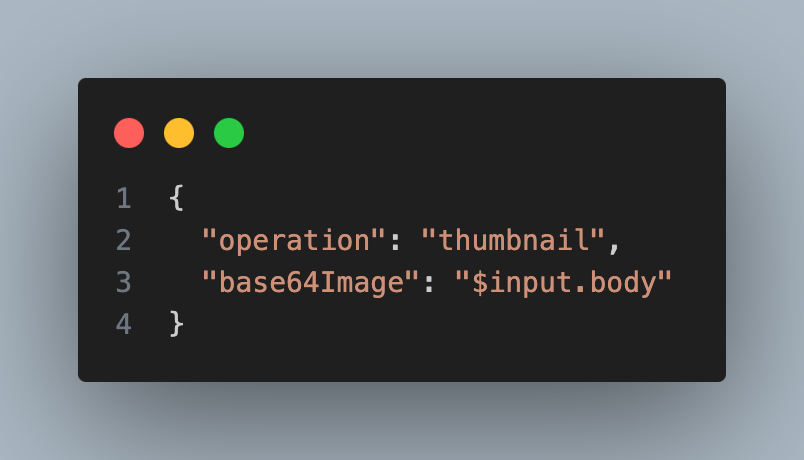
Pic 4.5: mapping template
The structure of the mapping template is tailored to meet the specific input requirements of the endpoint.
7. Choose Save.
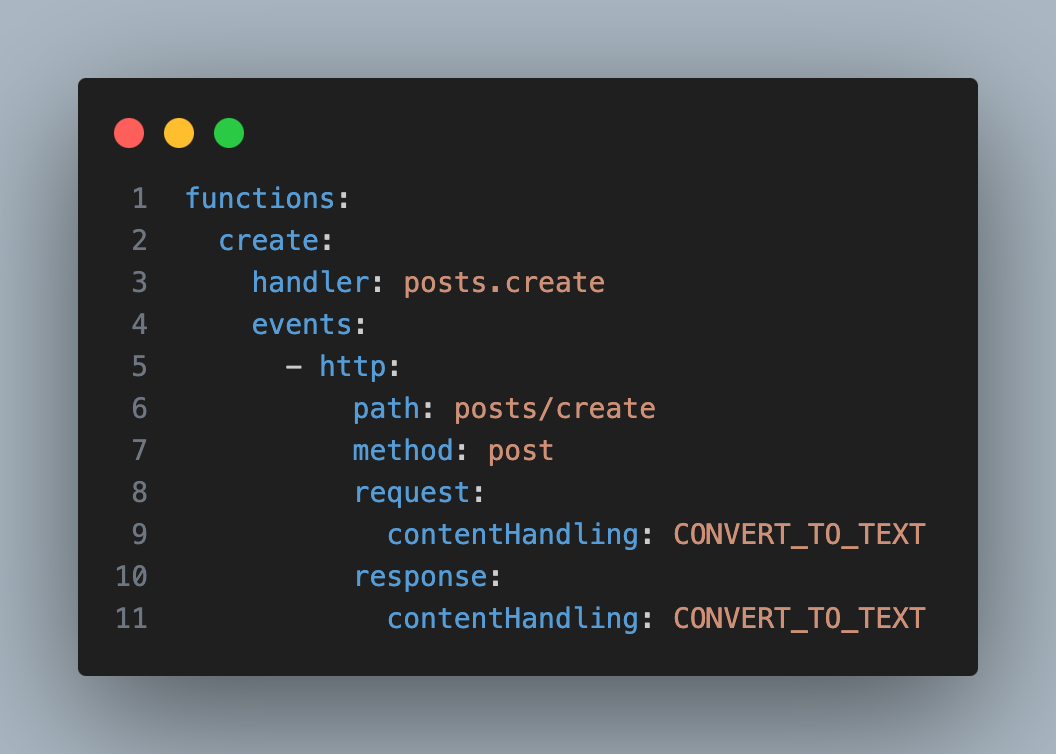
Pic 4.6: set up in serverless.yml
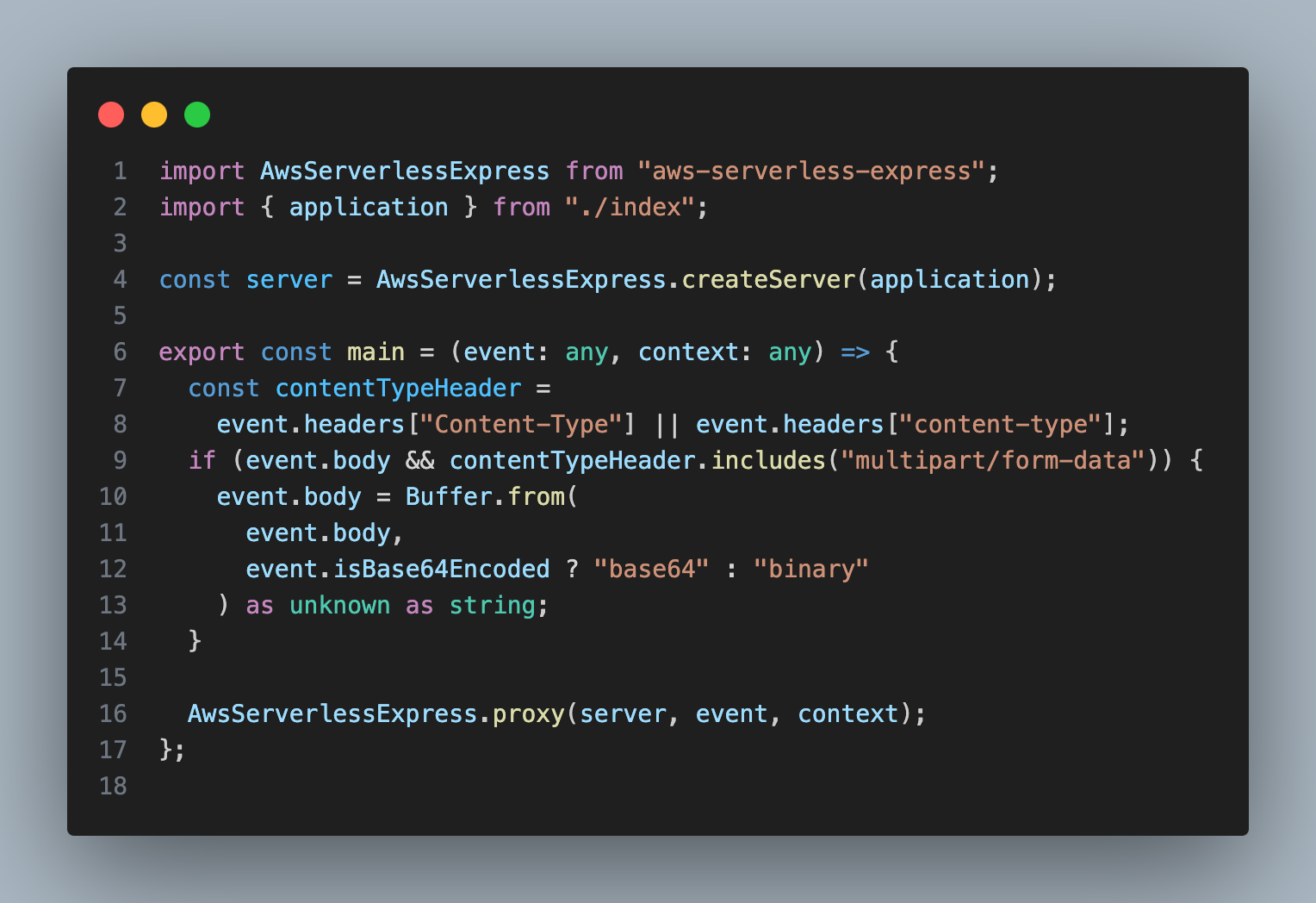
Pic 4.7: set up in code
5. Lessons Learned 3: Setup certificates and domain for a website
In this project, we utilize CloudFront for easy content distribution to users. For those who are not familiar, Amazon CloudFront is a web service that speeds up distribution of your dynamic and static web content to end users by delivering your content from a worldwide network of edge locations. When a user accesses content distributed via CloudFront, they are automatically directed to the nearest edge location for the fastest delivery. This guarantees optimal performance in content delivery. If the requested content is already present at that edge location, it is provided to the user without delay. Otherwise, CloudFront promptly fetches it from the designated Amazon S3 bucket or web server that serves as the authoritative source of the content.
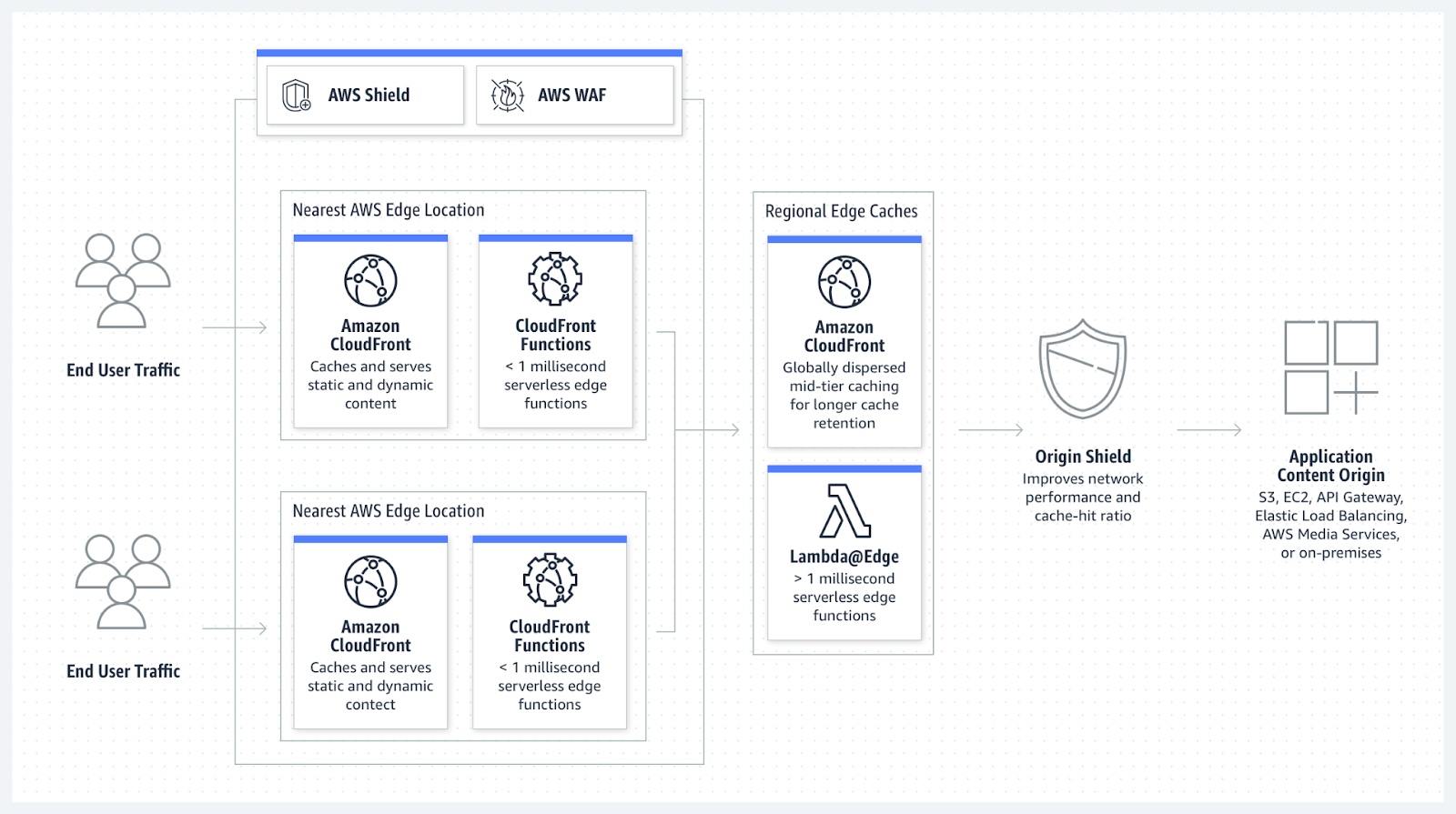
Pic 5.1: CloudFront overview. Source: AWS
By default, CloudFront provides us with a domain under the cloudfront.net domain. In my case, the domain is https://d1z2z7sv4jcg7v.cloudfront.net/. This domain name is quite cumbersome and difficult for users to remember. Therefore, when delivering the product to users, we need to configure a more user-friendly domain that is easier to remember and use. Additionally, we should also install an SSL/TLS certificate to ensure better protection for our website and applications.
To manage certificates, we use the AWS Certificate Manager service. You have the option to secure your AWS services with certificates by either generating them through ACM or importing certificates from external sources into the ACM system. In this case, I will use third-party certificates. Before proceeding to the certificate import step, you need to check the following conditions:
- Your key length must be 1024 bits, 2048 bits, or 3072 bits, and can’t exceed 3072 bits. Please be aware that ACM provides RSA certificates with a maximum key size of 2048 bits. If you require a 3072-bit RSA certificate, you’ll need to obtain it from an external source and import it into ACM. Once imported, you can then utilize the certificate with CloudFront.
- You must import the certificate in the US East (N. Virginia) Region.
- You must have permission to use and import the SSL/TLS certificate.
After meeting all the prerequisite conditions, we will proceed with the certificate import. You can import it either through the AWS CLI or the Console. I chose to import via the Console because of its user-friendly interface, which is easy for beginners like me to use.
- Open the ACM console at https://console.aws.amazon.com/acm/home. If this is your first time using ACM, look for the AWS Certificate Manager heading and choose the Get started button under it.
- Choose Import a certificate.
- Do as the image below:
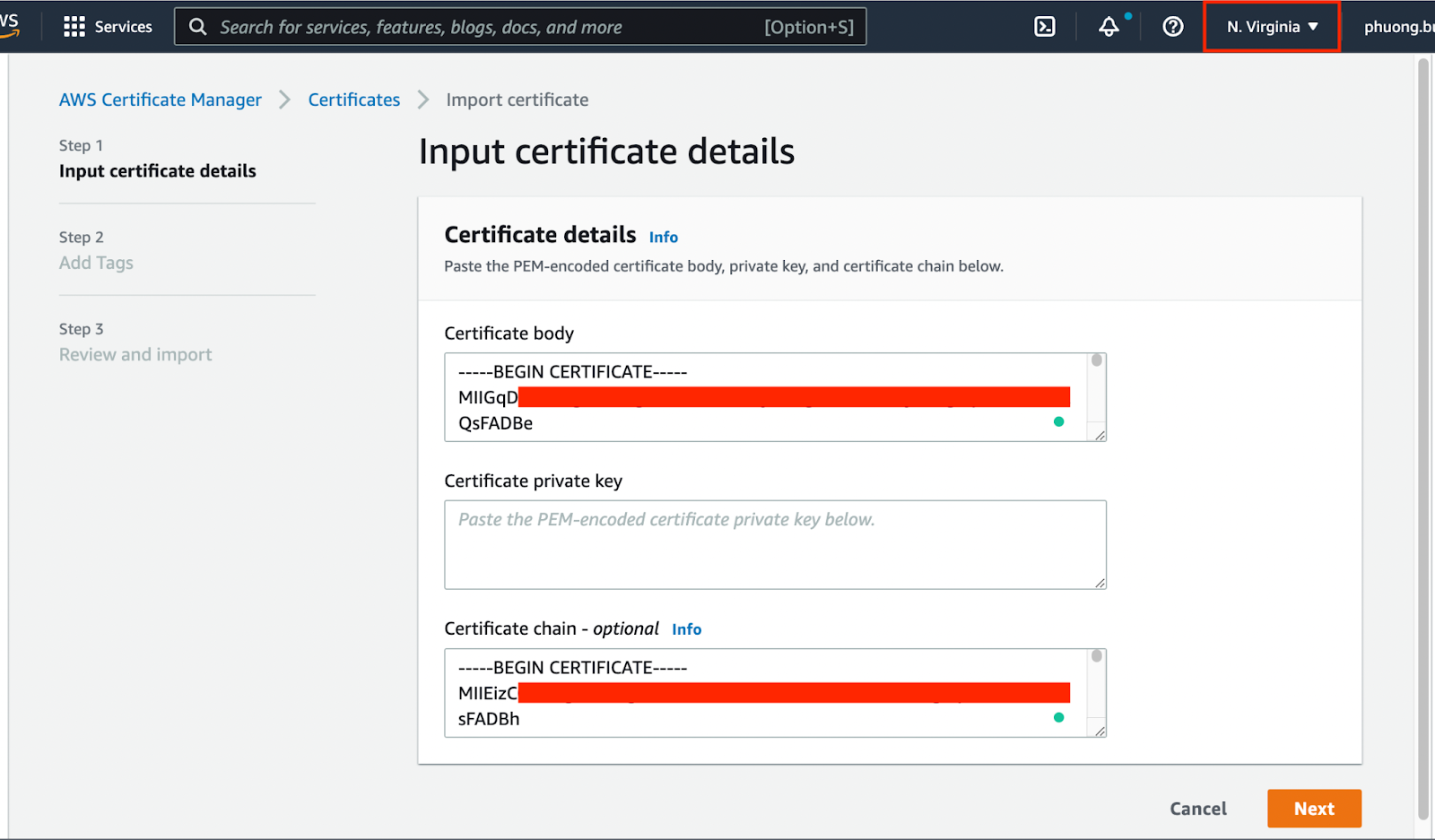
Pic 5.2: import certificate
To identify the Certificate body, Certificate private key, and Certificate chain, you need to refer to the instructions file received with the certificate. Following the example image below: we will use star_rich_portal.crt for the Certificate body, TrustedRoot.crt for the Certificate private key, and DigiCertCA.crt for the Certificate chain.
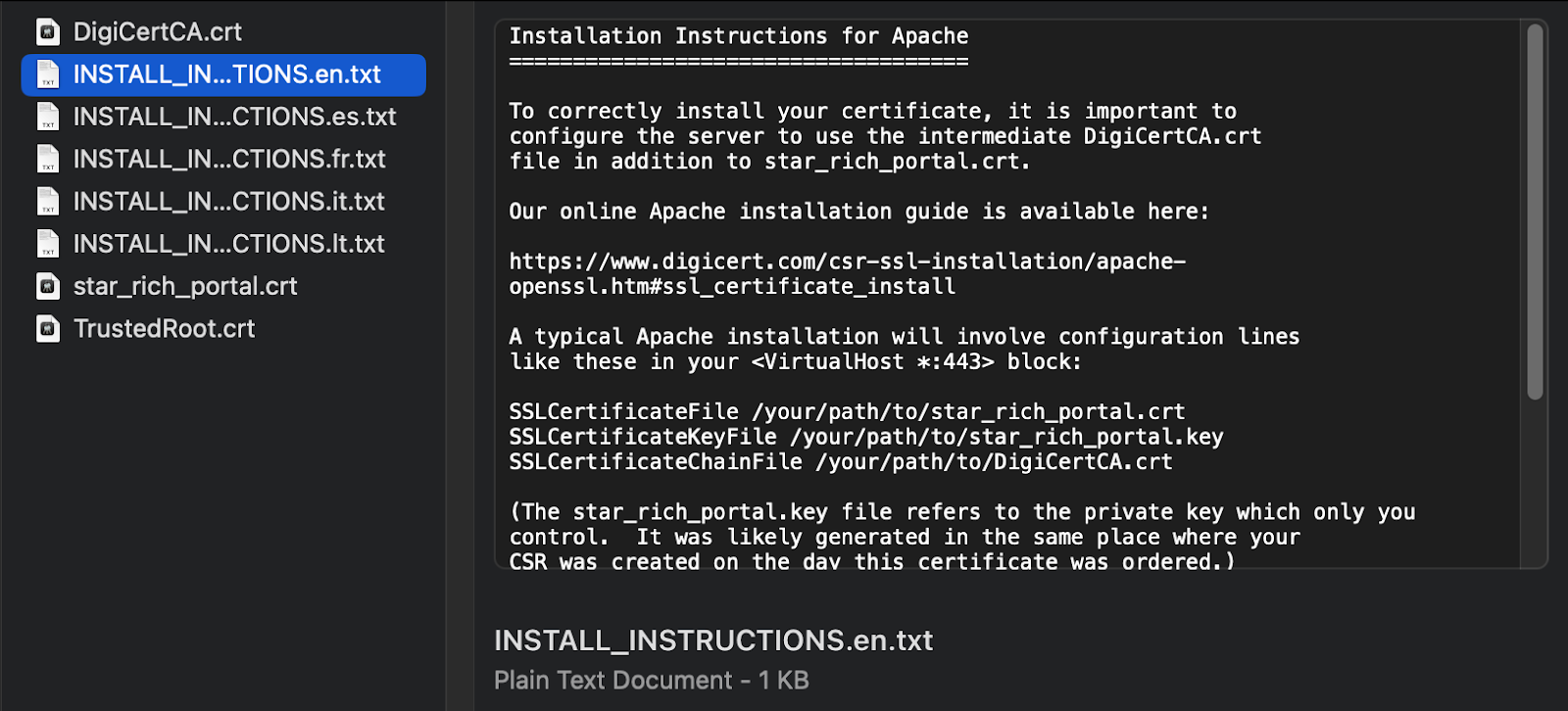
Pic 5.3: certificate
- Choose Review and import.
- On the Review and import page, check the displayed metadata about your certificate to ensure that it is what you intended. The fields include:
- Domains — An array of fully qualified domain names (FQDNs) that the certificate verifies.
- Expires in — The number of days until the certificate expires
- Public key info — The cryptographic algorithm used to generate the key pair
- Signature algorithm — The cryptographic algorithm used to create the certificate’s signature
- Can be used with — A compilation of services integrated with ACM that are compatible with the certificate type being imported.
- If everything is correct, choose Import.
After importing the certificate, we proceed to update the domain for the website.
Step 1: Open CloudFront → Select distribution needed to update
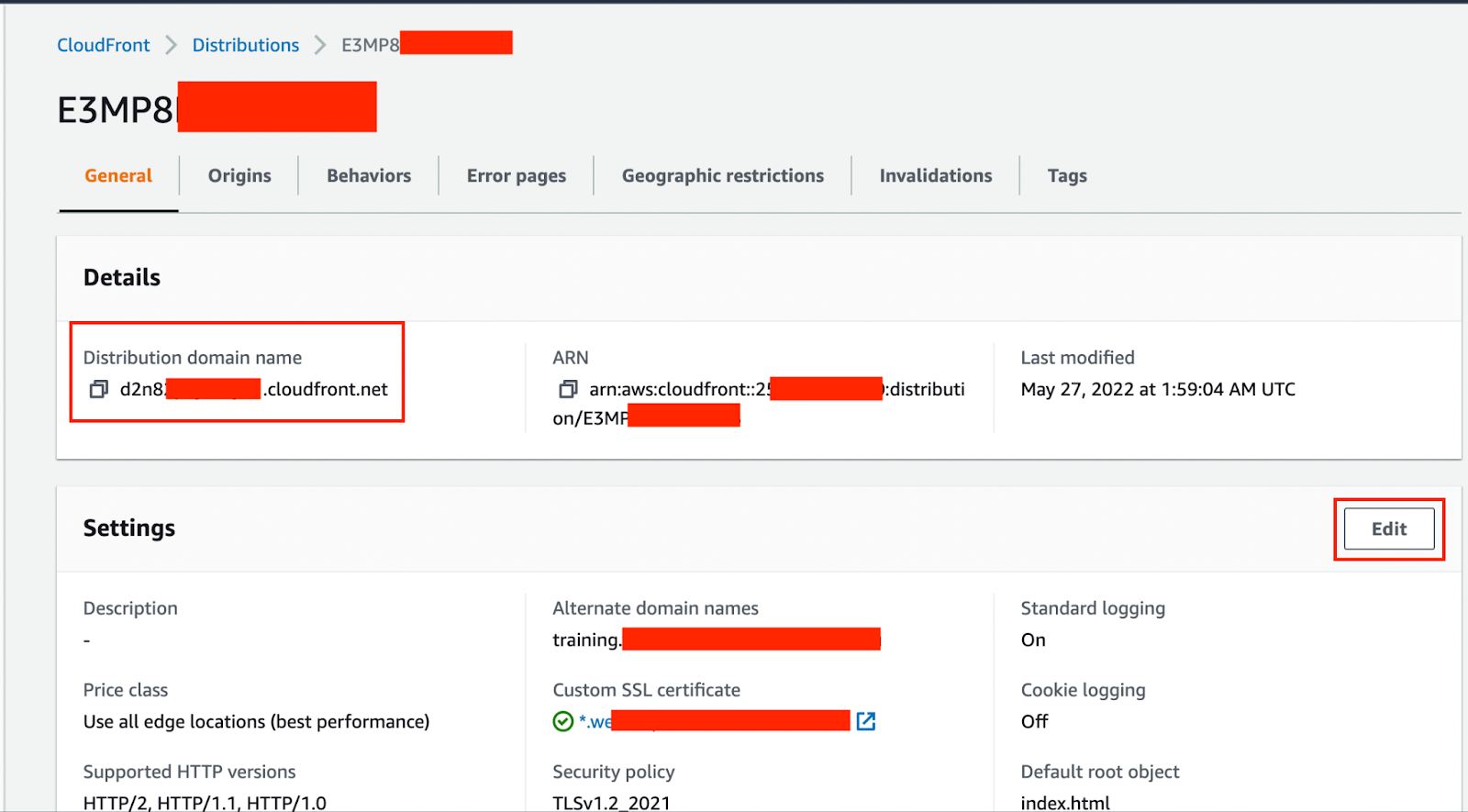
Pic 5.4: distribution example
Step 2: Add Alternate Domain Names (CNAMEs) and Choose an SSL Certificate
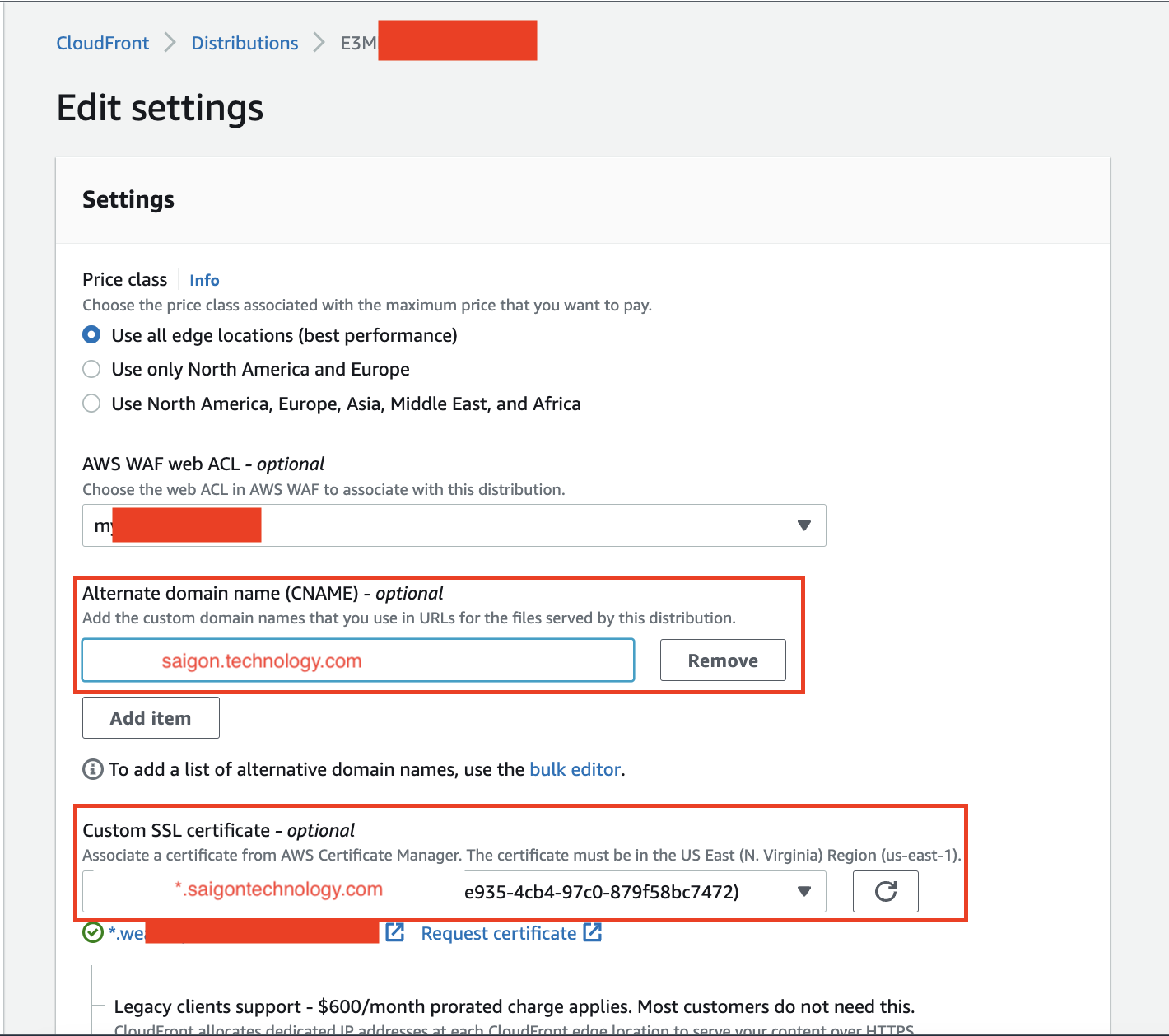
Pic 5.5: set up CNAME
The final step involves configuring the DNS service for your alternate domain name (like saigontechnology.com) to direct traffic to your CloudFront distribution’s domain name (such as d111111abcdef8.cloudfront.net). The specific method varies depending on whether you’re using Amazon Route 53 or a different DNS service provider. In this scenario, since I didn’t have the necessary access and control over the domain, I requested the client’s assistance with this task.
6. Conclusion
I have shared the first three lessons that I believe you will invariably encounter in any project. Each AWS service has its limitations and offers different functions and implementation methods. Therefore, it is crucial to thoroughly understand the services before proposing solutions to clients and executing the implementation.
Moreover, when I joined the project, despite my eagerness to learn new knowledge and my dedication to my responsibilities, I lacked substantial knowledge about BE development and AWS services. This gap led to overtime work, reliance on colleagues’ assistance, and some issues within the project. I consider myself fortunate because not every project tolerates inexperienced personnel, especially in significant projects related to finance or government. The mistakes I made did not result in severe consequences within the project’s scope but left me with valuable experiential lessons. However, these could have had unpredictable impacts in different project scopes, under other conditions, circumstances, or environments. Therefore, I encourage you to solidify your foundational knowledge thoroughly and robustly before seeking new challenges and responsibilities. Do not repeat the mistakes I made.
May your journey of learning be filled with delight.
Resources
- Demo source code: Repos’s link
References
- Amazon API Gateway quotas and important notes
- Lambda quotas
- How do I configure my CloudFront distribution to use an SSL/TLS certificate?
- Using custom URLs by adding alternate domain names (CNAMEs)
- Enabling binary support using the API Gateway console
- Offset and keyset pagination with PostgreSQL and TypeORM
- Amazon S3: First look and simple demo to upload image to S3 with Presigned url

Cloud Migration Services
Related articles

How To Deal With Tough Challenges In Cloud Migration

Cloud Computing in Healthcare: Technology Impact on the Industry

What is the Importance of Using Cloud Computing in the Healthcare Sector?

